
Google AI has announced a new audiovisual speech enhancement feature in YouTube Stories (iOS) that enables creators to make better selfie videos by automatically enhancing their voices and reducing noise. The new feature is based on Google’s Looking to Listen machine learning (ML) technology, which uses both visual and audio cues for isolating and separating the speech of a video subject from background sounds.
Introduced in November 2017, YouTube Stories lets channels with over 10,000 subscribers share Instagram-like “short, mobile-only videos… to connect with your audience more casually, on the go.” Creators use YouTube Stories to share content such as behind-the-scenes snippets and to stay more immediate and interactive with their followers.
To add their Looking to Listen technology to YouTube, Google researchers overcame a number of difficult challenges: all processing had to be done on on-device within the client app (no audio or video information would be sent to servers for processing); the model had to co-exist alongside other ML algorithms the YouTube app; and the algorithm had to run quickly and efficiently on a device while minimizing power consumption.

Introduced two years ago, Looking to Listen achieves state-of-the-art results in speech separation and enhancement, and its use of visual cues significantly improves performance over audio-only processing approaches when there are multiple people speaking. Researchers made optimizations and improvements on Looking to Listen so it could fit on YouTube Stories. The new model runs efficiently on mobile devices, while also significantly improving processing — from 10x real-time on a desktop to 0.5x real-time on a phone. The team conducted extensive testing to verify the tech performs consistently across different recoding conditions
YouTube creators usually want to leave some background sounds in their audio to provide context and a natural room sound, and to retain the general ambiance of a scene. The researchers found that an output that retains 10 percent original audio with a 90 percent produced clean speech channel works best in practice.
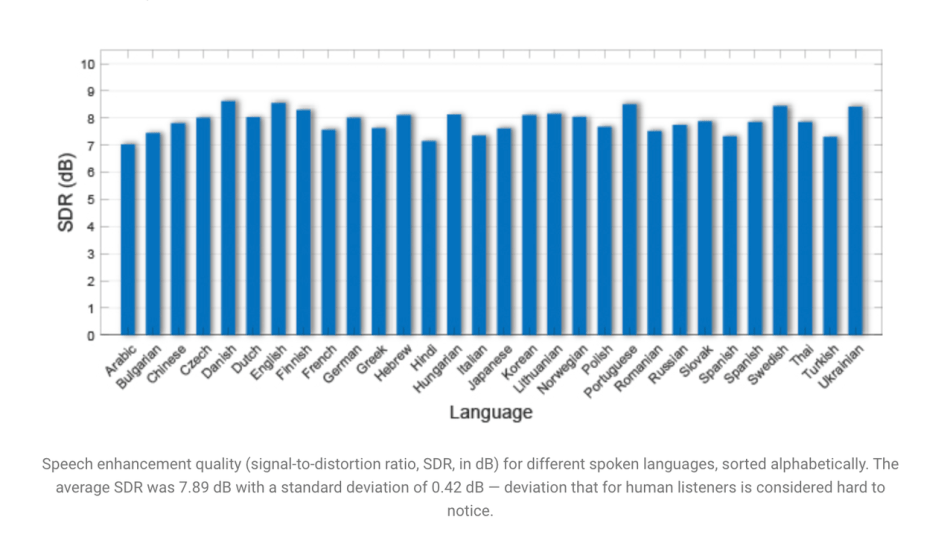
In the interests of fairness and inclusivity, the team tested the model across a range of speech and visual attributes to ensure it can handle different voices, languages and accents, as well as visual variations in age, skin tone, etc.
“Getting this technology into users’ hands was no easy feat. Over the past year, we worked closely with users to learn how they would like to use such a feature, in what scenarios, and what balance of speech and background sounds they would like to have in their videos,” write Google Software Engineer Inbar Mosseri and Research Scientist Michael Rubinstein in a blog post announcing the new YouTube Stories feature.
The paper Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation is on arXiv.
Analyst: Yuqing Li | Editor: Michael Sarazen; Yuan Yuan

Synced Report | A Survey of China’s Artificial Intelligence Solutions in Response to the COVID-19 Pandemic — 87 Case Studies from 700+ AI Vendors
This report offers a look at how China has leveraged artificial intelligence technologies in the battle against COVID-19. It is also available on Amazon Kindle. Along with this report, we also introduced a database covering additional 1428 artificial intelligence solutions from 12 pandemic scenarios.
Click here to find more reports from us.

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: Google AI Enables Speech Enhancement on YouTube Stories in Seconds – Full-Stack Feed
Pingback: [R] Google AI ‘Looking to Listen’ Tech Enables Speech Enhancement on YouTube Stories in Seconds – tensor.io
Pingback: Google AI Enables Speech Enhancement on YouTube Stories in Seconds | صحافة حرة FREE PRESS
Pingback: Google AI 'Looking to Listen' Tech Enables Speech Enhancement on YouTube Stories in Seconds – Increase Your Video Viewing Time Legally
YouTube on of the most popular social media now, with your YouTube channel you can make good and popular blog. I recommend look one site, if you want promote your YouTube safe. There is a great site where you can order real views, like, comments, followers and even more… You can found on this site. Just check it, maybe it will be very useful https://likigram.com/free-youtube-views/