
For the last decade, the massive deployment of deep neural networks has radically transformed research approaches. Particularly in natural language processing (NLP), innovations on deep neural networks have been continuously evolving to meet new market demands. Recently, there has been a growing interest in developing small and accurate NLP neural networks that can run entirely on smartphones, smartwatches and IoT devices.
Much research today is exploring ways to shift the development of NLP models so they can run on-device, rather than through high-tech data centers. Considering mobile devices often have limited memory and processing power, these NLP models must be small, efficient, and robust enough without compromising quality.
Google AI recently released the new trimmed-down pQRNN, an extension to the projection attention neural network PRADO that Google AI created last year and which has achieved SOTA performance on many text classification tasks with less than 200K parameters. PRADO’s example of using extremely few parameters to learn the most relevant or useful tokens for a task inspired Google AI researchers to further exploit its potential.
Unlike previous on-device neural models such as the lightweight text classification model self-governing neural networks (SGNN) based on locality-sensitive projections and focusing on short text classification, PRADO combines trainable projections with attention and convolutions to capture long-range dependencies for long text classification. Google AI researchers designed PRADO to learn clusters of text segments from words rather than word pieces or characters, and explain it’s essentially that core design that decreases the model parameters, “since word units are more meaningful, and yet the most relevant words for most (NLP) tasks are reasonably small.”
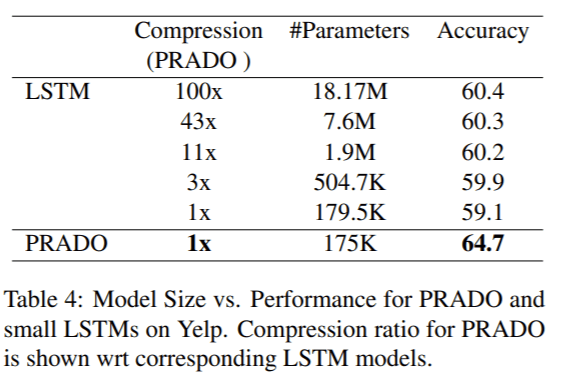

PRADO’s ability to learn clusters of text segments from words rather than word pieces or characters has enabled it to achieve good performance on low-complexity NLP tasks.
The pQRNN PRADO extension is composed of three building blocks. A projection operation converts tokens in the text to a sequence of ternary vectors, a dense bottleneck layer learns a per word representation relevant to the NLP task, and a stack of QRNN encoders learns a contextual representation from text input alone without employing any preprocessing.



PQRNN favourably compared with the SOTA NLP model BERT on text classification tasks on the civil_comments dataset, achieving near BERT-level performance but using 300x fewer parameters and with no pretraining. The on-device design underlying the new model has potential in various text classification applications such as spam detection, product categorization, sentiment classification, etc.
The paper PRADO: Projection Attention Networks for Document Classification On-Device is available on aclweb, and Google AI has open-sourced the PRADO model on GitHub.
Reporter: Fangyu Cai | Editor: Michael Sarazen

Synced Report | A Survey of China’s Artificial Intelligence Solutions in Response to the COVID-19 Pandemic — 87 Case Studies from 700+ AI Vendors
This report offers a look at how China has leveraged artificial intelligence technologies in the battle against COVID-19. It is also available on Amazon Kindle. Along with this report, we also introduced a database covering additional 1428 artificial intelligence solutions from 12 pandemic scenarios.
Click here to find more reports from us.

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: Google Approaches Bert-Level Performance Using 300x Fewer Parameters | صحافة حرة FREE PRESS
Pingback: Google Approaches Bert-Level Performance Using 300x Fewer Parameters - GistTree
Pingback: Google Approaches Bert-Level Performance Using 300x Fewer Parameters | Hacker News
Pingback: Google Approaches Bert-Level Performance Using 300x fewer Parameters with Extension of Its New NLP model PRADO - honynews.com
Pingback: Tech News: Google Approaches Bert-Level Performance Using 300x fewer Parameters with Extension of Its New NLP model PRADO
Pingback: Google Approaches Bert-Stage Performance The exhaust of 300x fewer Parameters with Extension of Its Novel NLP model PRADO - News Himalaya
Pingback: Google Approaches Bert-Level Performance Using 300x Fewer Parameters – Hacker News Robot
Pingback: Google Approaches Bert-Stage Effectivity Utilizing 300x Fewer Parameters - JellyEnt
Pingback: Google Approaches Bert-Level Performance Using 300x fewer Parameters with Extension of Its New NLP model PRADO – Emsi’s feed
Pingback: Google Approaches Bert-Level Performance Using 300x Fewer Parameters – HackBase