
Whether on a robot gripper in a high-tech factory or onboard an autonomous vehicle navigating busy city streets, accurate depth estimation is an essential element of computer vision systems across a wide range of tasks and applications. Performing accurate 3D scene reconstruction from image sequences is a problem that has been studied in the computer vision community for decades. Although lidar and special camera arrays can deliver the sort of data that makes 3D reconstruction easier, the most convenient and widespread image source for 3D reconstruction tasks is smartphones, which enable spontaneous hand-held, high quality video capture across almost any scene.
To take advantage of ubiquitous smartphone videos while overcoming challenges in this and other existing approaches — such as missing regions in the depth maps or inconsistent geometry and flickering depth — researchers from the University of Washington, Virginia Tech and Facebook have introduced an algorithm that can reconstruct dense, geometrically consistent depth for all pixels in monocular videos.

This research is based on a new video-based reconstruction system that combines the strengths of traditional and learning-based techniques. The method uses traditional Structure-from-Motion (SfM) to reconstruct the geometric constraints of pixels, but unlike traditional reconstruction methods that rely on special priors, this study instead uses priors based on learning — a convolutional neural network trained for single image depth estimation — to fill in the weakly constrained parts of the scene more plausibly than prior heuristics.

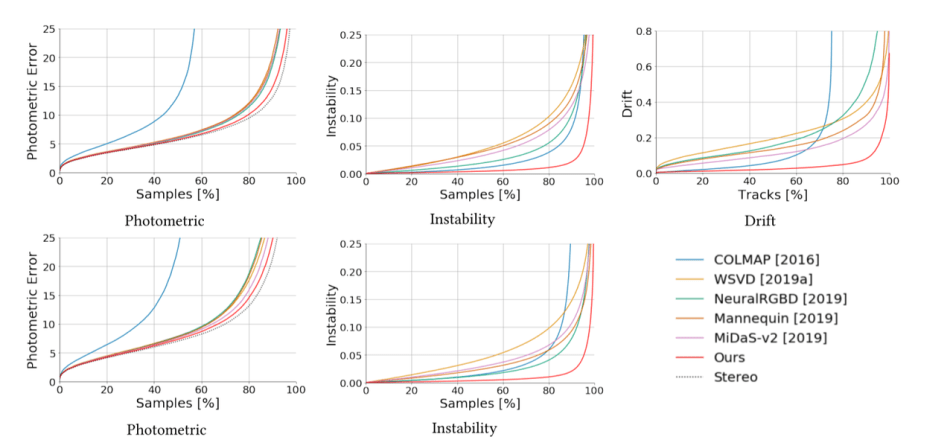
Quantitative validation results show that the proposed method achieves higher accuracy and a higher degree of geometric consistency than previous monocular reconstruction methods. Visually, the results of the proposed method also tend to be more stable. This algorithm can also handle hand-held captured input videos with a moderate degree of dynamic motion and can be applied to scene reconstruction and video-based advanced visual effects.
There are some limitations to the proposed depth estimation method. It does not support online processing, and the test-time training step takes about 40 minutes for a video of 244 frames and 708 sampled flow pairs. Author Jia-Bin Huang says the team’s next goal will be improving model speed, as the current high compute requirements make it difficult to use in real-time AR scenarios.
The researchers are also working on developing online and fast variants for practical applications.
The paper Consistent Video Depth Estimation is on arXiv. The project page is on GitHub. The paper has been accepted by SIGGRAPH 2020, and authors say they plan to open-source the code.
Author: Yuqing Li | Editor: Michael Sarazen
Can this be done in real-time ? Seems it would need to process the complete video for random reference points to calculate the depth map.