
Although convolutional neural networks have reached Superman level on image classification tasks, adversarial examples remain the kryptonite that can mysteriously defeat even SOTA models.
“An adversarial example is an image that you have intentionally crafted to screw up a network after training it.” So says Nicholas Frosst, a Google Brain Research Engineer working on the adversarial examples problem with Turing Award winner Geoffrey Hinton’s Toronto team. In his keynote at the recent Re•Work Deep Learning Summit in Montréal, Frosst discussed a new approach to the problem, deflecting adversarial examples with capsule reconstruction networks.
There have been many attempts from many researchers to create adversarial example detection and defence techniques, but none have proven sufficiently effective, especially against defense-aware attacks.

Frosst began his talk by noting that humans can often understand a thing sufficiently well given just a simple general outline of the thing. In machine learning there are also outlines used for recognizing things, and classes of things and decision boundaries. This he illustrated with red and green dots in two dimensions that a machine learning model would need to classify. It’s easy to train a model and visualize its decision boundary to see where it classified things wrong or right. Frosst said however that in most cases in his research in the image domain, where the number of dimensions can reach into the thousands, the decision boundary is not so easy to locate or visualize.
Just as calculus is used during network training to update weights and improve classification accuracy, Frosst explained, the same procedure can be “flipped on its head” and applied to images to make a network perform poorly and misclassify. Especially in huge dimensional spaces, adversarial examples are very tough to beat.
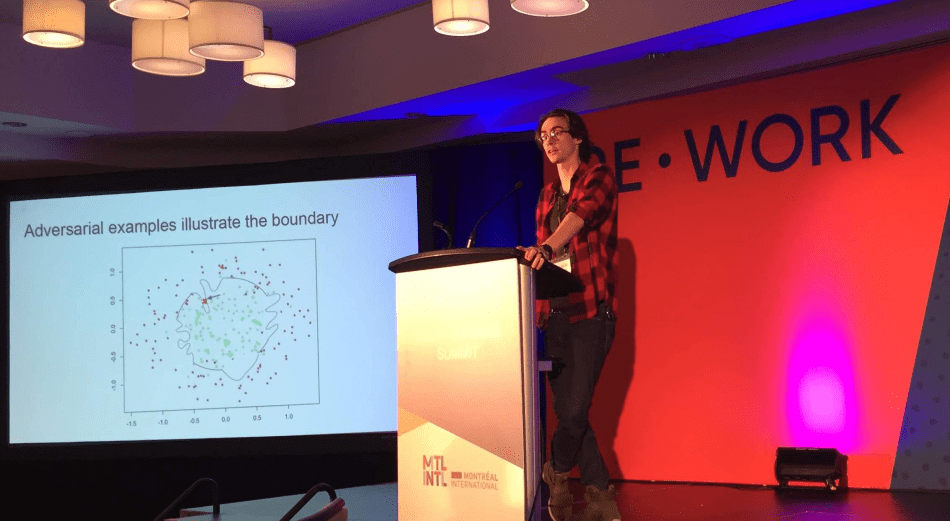
When adversarial attacks first appeared a couple of years ago, Frosst says “a lot of people freaked out.” The machine learning community responded by creating adversarial attacks and then seeking methods to classify them as such: “Someone presents a defense that is robust against an adversarial attack and then someone presents a new attack which breaks that defense and the cycle repeats. That’s been going on for a long, long time.”
Frosst says when defence strategies shifted from classifying adversarial attacks to simply detecting them, “this too fell into the same ongoing cycle. And this is where we are now.”
Frosst joked about researchers’ “emotional response” to adversarial examples, mocking the oft-cited concern that self-driving cars might not detect a stop sign modified by an adversarial attack and just drive straight through. “That sounds like a bad situation. But if you wanted to screw up an autonomous vehicle and have it not see the stop sign, you could just take the stop sign down. That turns out to be a lot easier…”

Frosst says a fundamental issue with adversarial attacks is that the machine learning community wrongly assumed the models they had successfully trained on one data distribution would behave the same way on other data. He believes a new approach is required.
The direction Frosst and his team are working on involves deflecting adversarial attacks using class-conditional generative models and capsule reconstruction networks, a new type of layered neural network that aims to operate more like human perception. The approach avoids what Frosst calls “the cycle problem,” creating models he believes can perform classification tasks more like humans do.
Frosst says this refined discernment can foil attempts to adversarially perturb inputs at source, essentially forcing the attacker to produce inputs which semantically resemble “some new thing that is the target class.”


Frosst closed his talk saying he believes this research “is moving in the right direction of having networks which behave in the way we think they’re going to behave, and subsequently stopping the emotional response the machine learning practitioners get when confronted with the existence of adversarial examples.”
The paper Deflecting Adversarial Attacks can be accessed via ICLR 2020 reviews. A related 2018 Google Brain paper, DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules, is on arXiv.
Journalist: Fangyu Cai | Editor: Michael Sarazen
0 comments on “Google Brain’s Nicholas Frosst on Adversarial Examples and Emotional Responses”