
Generative Adversarial Networks (GANs) have revolutionized high-fidelity image generation, making global headlines with their hyperrealistic portraits and content-swapping, while also raising concerns with convincing deepfake videos. Now, DeepMind researchers are expanding GANs to audio, with a new adversarial network approach for high fidelity speech synthesis.
Text-to-Speech (TTS) is a process for converting text into a humanlike voice output. One of the most commonly used TTS network architectures is WaveNet, a neural autoregressive model for generating raw audio waveforms. But because WaveNet relies on the sequential generation of one audio sample at a time, it is poorly suited to today’s massively parallel computers. That’s why GANs, as an effective parallelisable model, are a viable option for more efficient TTS.
DeepMind explored raw waveform generation using GANs composed of a conditional generator for producing raw speech audio and an ensemble of discriminators for analyzing the audio.
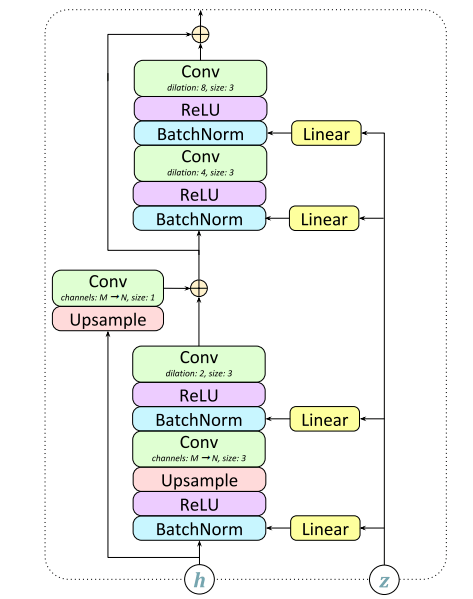
In the GAN-TTS process the input G is a sequence of human speech with linguistic features (encoded phonetic and duration information) and pitch information (logarithmic fundamental frequency) at 200Hz. The generator learns how to convert the linguistic features and pitch information to raw audio. The generator has seven “GBlocks,” each containing two skip connections: the first performs upsampling if the output frequency is higher than the input; the second contains a size-1 convolution when the number of output channels does not match the input channels. The output is a raw waveform at 24kHz.

Instead of using a single discriminator, DeepMind used Random Window Discriminators (RWDs) for random windows with different sizes. In addition to their data augmentation effect, RWDs are more suitable for analyzing audio realism and how well it corresponds to the target utterance. The discriminator is composed of DBlocks, and the entire structure is shown below:

DeepMind compared their model with previous research using mean opinion scores (MOS) to evaluate performance.

The results confirm that the GAN-TTS technique can generate highly-fidelity speech, with the best model achieving an MOS score of 4.2, only 0.2 below state-of-the-art performance.
The paper High Fidelity Speech Synthesis with Adversarial Networks is on arXiv.
Author: Hecate He | Editor: Michael Sarazen
So it’s not better than their older technology WaveNet?
Generative adversarial networks have seen rapid development in recent years and have led to remarkable improvements in generative modelling of images. However, their application in the audio domain has received limited attention, and autoregressive models, such as WaveNet, remain the state of the art in generative modelling of audio signals such as human speech. This is why the introduction of the GAN-TTS technique is so exciting.
nice topic