
Data is the fuel that drives machine learning, and data augmentation techniques are being widely deployed in fields such as natural language processing, computer vision and speech recognition to expand and enrich labeled training databases. Data augmentation can be achieved for example by rewriting a sentence or recapturing an image from different angles, but such approaches tend to be limited to supervised learning.
Researchers from Carnegie Mellon University and Google Brain have now proposed an unsupervised data augmentation (UDA) technique that significantly improves semi-supervised learning (SSL) by conducting data augmentation on unlabeled data. The new UDA method has been open sourced on Github.
Google researchers explain that unlike supervised data augmentation, UDA uses both labeled data and unlabeled data. The core idea behind the process is to first minimize a divergence metric between the consistency loss computed on unlabeled data and its augmented version, and then compute the final loss by jointly optimizing both the supervised loss from the labeled data and the unsupervised consistency loss from the unlabeled data.
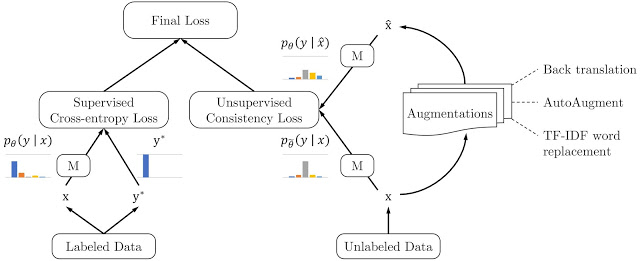
The researchers also introduced Training Signal Annealing (TSA), an additional training technique which gradually releases labeled examples’ training signals without overfitting them as the model is trained on an increasing number of unlabeled examples. To deal with the problem of over-flat predicted distributions when the number of labeled examples is very small, researchers proposed three techniques — confidence-based masking, entropy minimization, and softmax temperature controlling — to sharpen predicted distribution. Researchers found that using both confidence-based masking and softmax temperature controlling achieved the most effective results with limited labeled data.
Out-of-domain unlabeled data is easy to collect, but the class distributions of out-of-domain data are often mismatched to the data on hand. Researchers present a technique called Domain-relevance Data Filtering to help avoid the harmful effects of mismatched class distributions and obtain relevant out-of-domain data for a task.
UDA shows great capacity with small labeled training data. On the IMDb Sentiment Analysis task, UDA achieved an error rate of 4.20 on 50,000 unlabeled examples with only 20 labeled samples given, outperforming the previous SOTA model (4.32 error rate on 25,000 labeled samples). UDA also shows robust results in large trained data environments.


UDA outperforms all existing SSL methods including VAT (virtual adversarial training: a regularization method for supervised and semi-supervised learning) on the standard semi-supervised learning benchmark CIFAR-10 and SVHN. UDA achieves an error rate of 5.27 with 4,000 examples given, outperforming the fully supervised model with 50,000 examples given on the CIFAR-10 image classification task. UDA also breaks the previous SOTA semi-supervised record with an error rate of 2.7 on CIFAR-10 when working with the more advanced architecture PyramidNet+ShakeDrop. On SVHN, UDA trained with only 1,000 labeled examples performs as well as a fully supervised model trained with up to ~70,000 labeled examples.
The paper Unsupervised Data Augmentation for Consistency Training is on arXiv.
Author: Herin Zhao |Editor: Michael Sarazen
0 comments on “Google Brain & CMU Advance Unsupervised Data Augmentation for Semi-Supervised Learning”