
There are some things that some people just don’t want showing up on their websites, and this has spawned a wide range of activities and technologies that fall under “content review.” Initially done manually by Community Operations teams, content review is now increasingly automated, relying on computer vision and image classifier models and huge datasets to train AI systems to filter inappropriate information. Comprehensive collections of naughty and/or nasty images are however difficult to obtain and rarely open sourced.
Last month Synced introduced a GitHub project (NSFW Data Scrapper) that includes a 220,000 NSFW (not safe for work) image dataset built by data scientist Alexander Kim to enable machine learning systems to perform content review. The project garnered interest from the computer science community, receiving over 7000 stars on GitHub in just one month. There were however a few shortcomings: the categories were not well-defined, and many images were either misclassified or should not have been in the dataset.
Paris-based data scientist Evgeny Bazarov (GitHub name “EBazarov”) has now open-sourced a new content review project, “NSFW Data Source URLs.” This is a much larger, high-quality image dataset of sexually explicit images containing over 1.58 million data volumes in 159 categories.
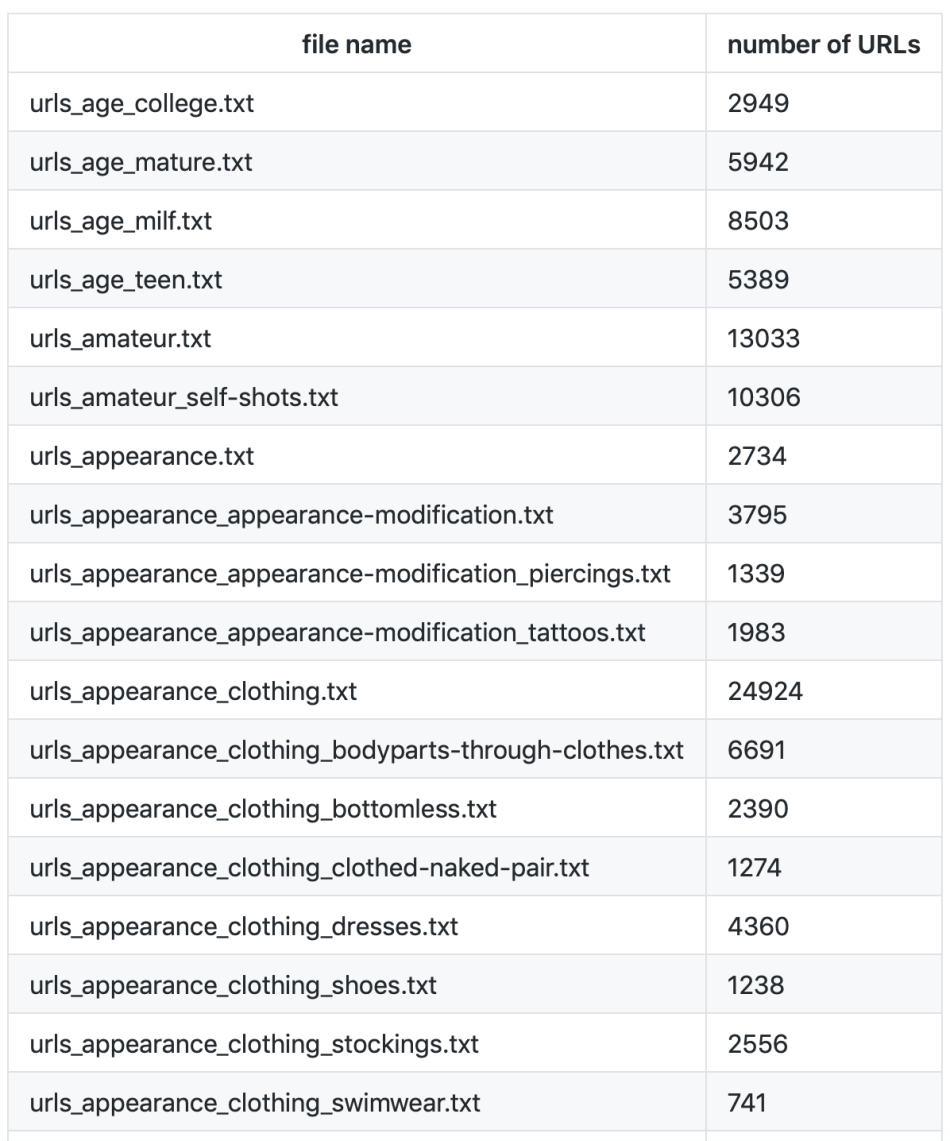
With its huge data volume and fine-grained categories, Bazarov believes the new dataset can help improve the accuracy of image classifiers or generative models. The project also provides corresponding image hyperlinks, similar to the NSFW Data Scrapper. Different categories and subcategories have their own .TXT files, and all hyperlinks are stored in .TXT text.
NSFW Data Source URLs guide:
In folder raw_data you will find different txt files each of them contains list of URLs, here some stats for this set:
- 159 different categories
- in total 1 589 331 URLs
- after downloading and cleaning it’s possible to have ~ 500GB or in other words ~ 1 300 000 of NSFW images
NOTE
- After downloading is highly suggested to clean your dataset, for example:
- delete duplicates
- remove images that was banned/deleted (they have a special image placeholder)
- find out corrupted data and remove it also
- etc
- Pay attention to noise, some resources provide highly mixed data of NSFW and neutral images
- This repository helps in retrieving NSFW images and there’s no special URLs for neutral content
NSFW Data Source URLs is a rare, open-source, restricted-level image dataset. Its release is expected to strengthen the robustness of current NSFW classification models, and bring further quality improvements to AI content review systems. It might even reduce some of the nastiness that Community Operation teams are regularly exposed to.
More information on the NSFW Data Source URLs is available on the project’s GitHub page.
Author: Herin Zhao | Editor: Michael Sarazen
It is important to remember that the fame of a company is a long and time-consuming process, it is alas impossible to wake up rich and famous without labor and investment, but it is quite possible to reduce the costs of marketing communications, images for websites and advertising.
Now there are many ways to get information about potential consumers without even contacting them, read more about online and offline marketing. For example, start by exploring social networks. In this way, you can find out their interests based on information about which publics they subscribe to, what they comment on, what content prevails in their feed, how they look, what places they visit, and so on.