
A cooperative research group from Google, Stanford, and Johns Hopkins has proposed “Auto-DeepLab,” a new method which utilizes hierarchical Neural Architecture Search (NAS) for semantic image segmentation. The project team includes top AI researchers Director of the Stanford Vision Lab Fei-Fei Li; and UCLA Center for Cognition, Vision, and Learning Director Alan Yuille.
Semantic image segmentation is an important a computer vision task that assigns a semantic label to every pixel in an image. Neural Architecture Search is a key AutoML process that has already been successfully used for other image classification tasks, and the team explored ways to extend NAS to dense image prediction problems. Existing methods usually focus on searching the cell structure and hand-designing an outer network structure. Researchers proposed searching the network level structure in addition to the cell level structure, as many more architectural variations for dense image prediction can be found at the network level.

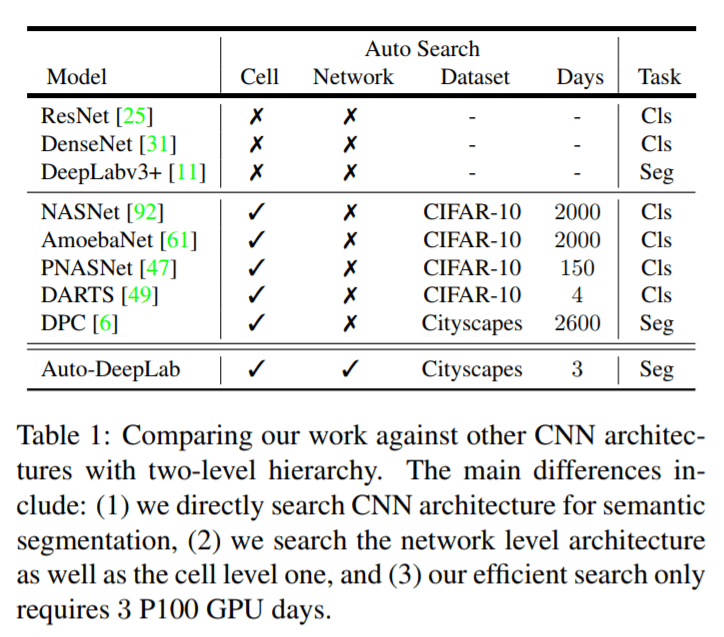
The researchers also developed “a differentiable formulation that allows efficient gradient-based architecture search over two-level hierarchical search space,” which only requires three days on a P100 GPU, making it 1000x faster than the DPC model (previous SOTA, see Table 1).
Evaluations were performed on three datasets — Cityscape, PASCAL VOC 2012, and ADE20K — to compare the work with state-of-the-art architectures.



As seen in the detailed evaluation results presented in Table 4 to Table 7, the new Auto-DeepLab method easily outperforms previous SOTA architectures when there is no pre-training. It can also perform comparably with top ImageNet-pretrained models, and even outperforms some of them.
The paper Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation is on arXiv.
Author: Mos Zhang | Editor: Michael Sarazen
An update: Alan Yuille left UCLA a few years ago. He is at Johns Hopkins full-time as a Bloomberg Distinguished Professor!
Pingback: Applied Sports Science newsletter – January 22, 2019 | Sports.BradStenger.com
13313113311331131331131313
After several unsuccessful attempts to find a good casino for players from Australia, I came across a really decent option. The interface is modern, everything works stably, and registration takes a few minutes. Jackpot Jill Casino has become my main gambling platform. I withdraw winnings to my card, and there were no problems. I recommend it to anyone who appreciates convenience and honesty.
Auto-DeepLab sounds like a significant advancement in the field of semantic image segmentation. The ability to leverage hierarchical Neural Architecture Search (NAS) to enhance performance is impressive, especially considering the speed improvements it offers over previous models. As a resident of Germany, I’m particularly interested in how such technologies can be applied in real-world scenarios, especially in industries like automotive and healthcare. For more insights, check out spinogambino. It’s exciting to see global collaboration driving innovation in AI research. The results you shared indicate that we are on the brink of even more breakthroughs in this area.
The advancements in semantic image segmentation through methods like Auto-DeepLab are incredibly exciting for the AI community, especially considering their potential applications in various industries. As someone residing in Germany, I see the importance of such technologies in enhancing computer vision tasks across sectors like automotive and healthcare. The use of hierarchical Neural Architecture Search to improve accuracy and efficiency is a game changer. It’s fascinating to observe how these innovations can lead to better models without extensive pre-training. For anyone interested in exploring further, you can check out glitz bets. The implications of these advancements could be vast, influencing how we approach problem-solving in AI. I look forward to seeing how this research evolves!
Seeing how gold reacts sharply to global news, leverage needs careful control. This morning in Dubai, checking positions on a tablet https://roboforex.com/ offered leverage up to 1:2000, but using a smaller portion of that kept trades more controlled. Gold often moves quickly, so entering with smaller positions and waiting for confirmation worked better. Their spreads starting from 0 pips also affect entry precision. Over time, focusing on consistent execution instead of large positions changed how results developed.