
ABSTRACT
Batch processing of dynamic graphs is a very common technique for a variety of applications, such as computer vision and natural language processing. However, due to the varieties of type and shapes between distinct data, batch processing with a static graph over such dataset is almost impossible with current frameworks and libraries.
In this work (published at ICLR 2017), M. Looks et al. from Google introduced a state-of-the-art algorithm called ‘Dynamic Batching‘, and developed a corresponding TensorFlow-based library called ‘TensorFlow Fold‘, that are able to cross the obstacles of batching with dynamic computation graphs.
This technique utilizes the static graphs generated by traditional libraries to emulate dynamic computation graphs of arbitrary shape, and not only can batch operations between different input graphs, but also among the various notes within a single input graph.
BACKGROUND
Computations over data-flow graphs is a popular trend for deep learning with neural networks, especially in the field of cheminformatics and understanding natural language. In most frameworks, such as TensorFlow, the graphs are static, which means the batch processing is only available for a set of data with the same type and shape. However, in most original data sets, each data has its own type or shape, which leads to a problem because the neural networks cannot batch these data with a static graph. This kind of problem is the so-called Dynamic Computation Graphs (DCGs). DCGs suffer from inefficient batching and poor tooling. Researchers achieved several breakthroughs of DCGs in recent years, in the domain of sentiment classification and semantic relatedness. However, most practitioners still avoid batching directly over dynamic graphs. Thus a new algorithm is required to overcome this limitation.
DYNAMIC BATCHING
Several principles of processing with Dynamic Batching:
1. Input data:
The input data of the neural network can be a set of data with different shapes, which means the computation graphs for each distinct data can be different.
2. ‘operations‘ and ‘ops‘:
The distinction between two concepts that seems similar, but are actually different.
- Individual operations: such as addition or matrix-multiply, is referred to as ‘ops‘, which appear as nodes in a graph.
- Functions over tensors: such as a feed-forward layer or LSTM cell, is referred to as ‘operations‘, which appear as sub-graphs in a graph.
Dynamic Batching only handles ‘operations‘ , rather than ‘ops‘.
3. input & output of an operation:
The type of inputs (b, x1, x2, ..., xn) & outputs (b, y1, y2, ..., yn) for an operation should be ‘tensor types‘. All of them should be specified in advance and fixed during the process so that operations can be changed respectively.
4. Brief process principle:
Each distinct data has its own computation graphs, which consists of various operations at different depth in the current graph. Dynamic Batching will replace (Rewriting Process) the previous graph by computing all data of the same operation which occurs at the same depth.
5. Rewriting process:
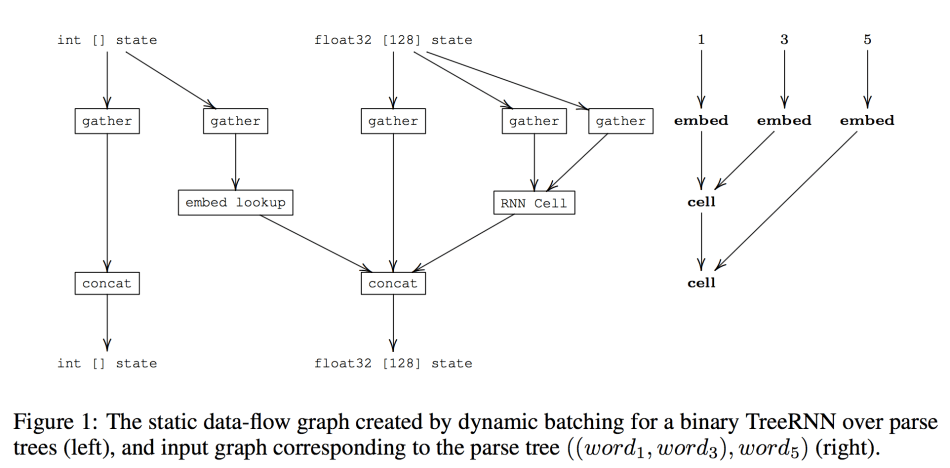
Dynamic Batching will insert two different operations: ‘concat‘ (for the word ‘concatenate’) and ‘gather’ into the graph to ensure the data stream flows smoothly between the currently batched operations.
6. In the TensorFlow implementation:
d represents the depth of each node in the graph, which is also an iterator of the while-loop later.
All inputs for an operation will be gathered by ‘tf.gather‘ before the execution of this operation, and all the outputs of the operation will be concatenated with ‘tf.concat‘. All of these ops are executed in a while-loop.
7. While-Loop:
Each variable has two parameters: t for tensor type and d for depth. The operations, which will work on these variables, will also be defined with two parameters t and d respectively.
The while-loop iterates through the depth d of the input graphs. The loop maintains [state variables for tensor type t] and [the output of tf.concat for type t & iteration d] and then feeds them into [the tf.gather at tensor type t and iteration d+1]
Figure 1 represents the static data-flow graph at depth d, which shows the move of variables within a single iteration step.
EXPERIMENTAL RESULTS
For the experiment, the authors developed a Tensorflow-based library named ‘TensorFlow Fold’.
They carried out an experiment to test the performance of this library. Since native TensorFlow is unable to process graphs of various shapes, they executed models generated by both Dynamic Batching (marked as ‘dynamic’) and manual batching (marked as ‘manual’) on a batch of random graphs with the exact same shape. The test simulated a best-case scenario, where all operations can be batched together.
Additionally, a third test group was carried out (marked as ‘fully dynamic’), in which each graph owns its unique shape. Therefore, there was no contrast group for this group.
From the table below, they concluded that for the same performance, the cost (time consumption) of Dynamic Batching with TensorFlow Fold was significantly lower than manual batching. Moreover, the speed of batching and similarity of the input graphs are essentially unrelated, which means the performance of Dynamic batching is excellent and stable.

COMBINATOR
Simplification examples: tasks like connecting a set of words of various length into a sentence. They introduced several combinators working directly on single blocks (or functions) which operate on elements (here the input words).
Map(f)yields a vector[f(x1), f(x2), ..., f(xn)]: applies a blockfto each element of the input words, so that words can be embedded into a vector.
Fold(f, z)yields af(...g(g(z,x1), x2), ...xn): appliesfsequentially in a leftward chain to run an RNN over a sequence.
Reduce(g): yieldsg(Reduce([x1, x2, ...,xn]), Reduce( [x(n/2+1), ... xn] )): appliesfin a balance tree (graph), e.g. max-pooling over the words.
One advantage of Dynamic Batching algorithm is that there is no need to pad or truncate words or sentences to the same length, which is a great convenience for users.
Combinator library not only aims for the simplification of constructing models for users, but also shows the advantage of Dynamic Batching in implementing deep learning models at a higher level of abstraction. They carried out some experiments of implementation of N-ary Tree-LSTMs for sentiment analysis, and their results are reported in the following tables:

The first column marked with ‘fine-grained accuracy‘ is measured for all trees and calculated based on the five possible labels. And the second column ‘binary accuracy‘ is measured only for trees with a non-neutral sentiment and is based on negative vs. positive classification.
From these tables, we can conclude that they have obtained a better accuracy for both methods than other previous works. At the same time, Dynamic Batching uses fewer script codes than others.
DISCUSSION
Most current deep learning libraries only support batch processing of static data-flow graphs. Hence, an efficient batch computation of dynamic computation graphs (DCGs) is almost impossible. Bowman introduced a SPINN architecture capable of computing over trees of various topologies, but it is limited with binary trees.
In this paper, M. Looks et al. from Google introduced a new algorithm: ‘Dynamic Batching’, and developed a Tensorflow-based library called ‘TensorFlow Fold’, which solved the DCGs problem in both theoretical and empirical fields.
With experimental implementations, they proved that their method is effective and more efficient than previous works. Next, they need to use more projects to verify the effectiveness of this algorithm. We hope that other similar DCGs problems can introduce this method, and there is considerable space to enhance the performance.
Paper Link: https://openreview.net/pdf?id=ryrGawqex
Author: Hao Pang | Editor: Joshua Chou
0 comments on “Deep Learning with Dynamic Computation Graphs”