
In the last few years, deep learning driven computer vision (CV) research has achieved impressive progress on classifying video clips taken from the Internet and analyzing the human actions therein. Such video-based tasks are challenging, as they require an understanding of the interactions between humans, objects and other content and context within a given scene, as well as reasoning over long temporal intervals. A successful CV model in this area needs to capture both spatial and long-range temporal interactions while also being “intelligent” enough to reason based on its observations.
In the paper Unified Graph Structured Models for Video Understanding, a Google Research team proposes a message-passing graph neural network (MPNN) that can explicitly model these spatio-temporal relations, use either implicitly (with supervision) or explicitly (without supervision) captured representations of objects, and generalize previous structured models for video understanding.

The Google Research paper Unified Graph Structured Models for Video Understanding focuses on spatio-temporal action recognition and video scene graph parsing, which require reasoning about interactions between actors, objects and their environment in both space and time. Because video is a high-dimensional signal, it is not feasible to train large convolutional networks to learn from video datasets. Instead, previous work has proposed graph-structured models to tackle this issue. Some of these studies only modelled the spatial relations in videos, ignoring the interactions that can evolve over time, while other studies took long-range temporal interactions into consideration but failed to capture spatial relations. Although some studies modelled spatio-temporal interactions within a keyframe, these approaches require additional supervision for explicit representations of objects.
The proposed MPNN method aims to build structured representations of videos by representing them as a graph of actors, objects and contextual elements in a scene. MPNN performs coherent modelling of both spatial and temporal interactions, and uses action recognition and scene graph prediction to understand the interactions between elements in the graph.

MPNN is a flexible model that can operate on a directed or undirected graph. Its inference consists of a message-passing phase and a final readout phase. In the message-passing phase, messages are first computed by applying spatial and temporal message-passing functions. An update function then aggregates the received messages to update the latent state. Intuitively, the update function is updated by aggregating the messages passed from its neighbours. Finally, a readout function uses the updated node features to classify tasks of interest.
Spatial connections include the relationships between actors, objects and scene context. MPNN models scene context by considering the features from each spatial position in the feature map. The researchers also add an implicit object model to enable the network to encode information about the scene and relevant objects without any extra supervision. It is also possible to augment contextual nodes with an explicit object representation by computing class agnostic object proposals with a Region Proposal Network (RPN).

The team notes that understanding actions often requires reasoning about actors who are no longer visible in the current frame, thus requiring large temporal contexts. MPNN models temporal interactions by connecting foreground nodes in a keyframe with all other foreground nodes in neighbouring keyframes. By setting the sampling rate no less than one, it is possible to consider a wider temporal interval in a more computationally efficient manner to train the entire model end-to-end. The researchers explain that because each foreground feature node is a spatio-temporal feature computed by a 3D CNN, selecting adjacent keyframes could result in the capturing of redundant information via temporal connections.
The researchers evaluated MPNN on scene graph classification (SGCls), predicate classification (PredCls), and spatio-temporal action detection tasks. They used the Action Genome dataset for video scene graph classification and prediction, and the AVA and UCF101- 24 datasets for spatio-temporal action recognition.
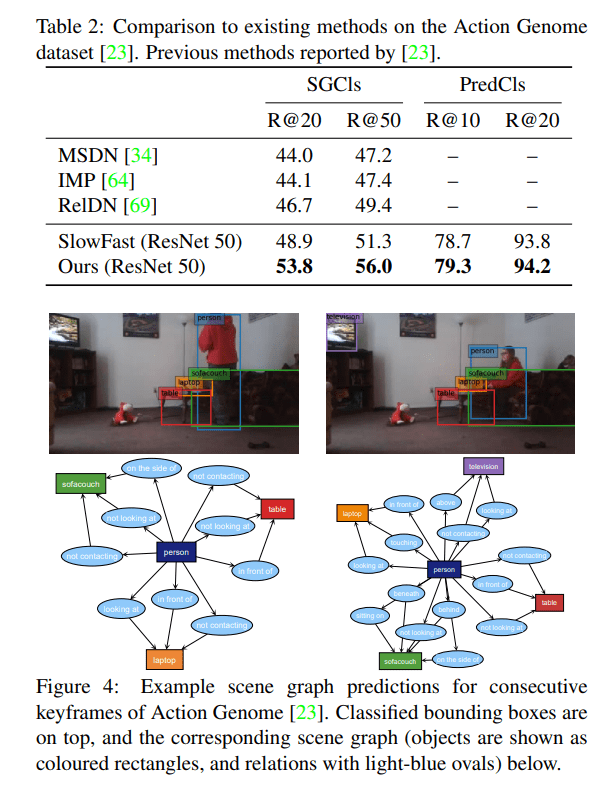
In video scene graph classification, the proposed spatio-temporal graph structured model improved substantially improved on the SlowFast-ResNet 50 3D baseline by 4.9 and 4.7 points for the R@20 and R@50 for SGCls respectively. The improvements over PreCIs were less pronounced, as the task is easier, leaving less room for improvement.


In spatio-temporal action detection on AVA datasets, the proposed model showed substantial improvements with either a 3D ResNet 50 or ResNet 101 backbone baseline. On UCF101-24, the model also outperformed all other approaches.

Overall, the researchers validated their novel spatio-temporal graph neural network framework’s ability to explicitly model both spatial and temporal interactions, achieving state-of-the-art results on two diverse tasks across three datasets.
The paper Unified Graph Structured Models for Video Understanding is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [N] Google Research’s SOTA GNN ‘Reasons’ Interactions over Time to Boost Video Understanding – ONEO AI
good article