
Reconstructing a 3D shape from a single 2D image is a classic computer vision challenge. Although the task almost seems to come naturally to humans, machines struggle to recover occluded or only partially observed surfaces. It’s believed what machines have been lacking is the ability to predict occluded surface geometry.
Inspired by how humans reconstruct shapes from flat images, a team of researchers from the University of British Columbia, Universidad Panamericana and the Vector Institute recently published the paper Front2Back: Single View 3D Shape Reconstruction via Front to Back Prediction. Their proposed framework outperforms state-of-the-art approaches for 3D reconstructions from 2D and 2.5D data, achieving 12 percent better performance on average in the ShapeNet benchmark dataset and up to 19 percent for certain classes of objects.
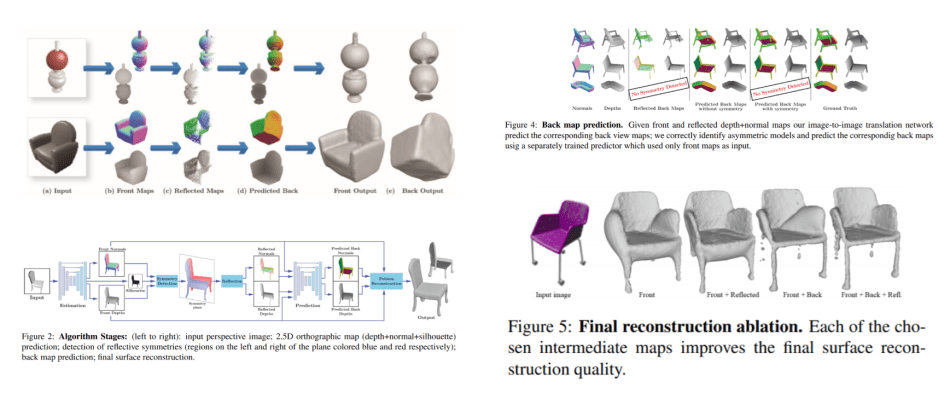
The researchers observed that the surfaces of most everyday objects show global reflective symmetries — where their shapes are reflected in the same size and shape across a line of symmetry. This encouraged the team to develop algorithms to predict the back view of an object even when only the front view is available. The researchers also observed that the opposite orthographic views of 3D shapes share consistent silhouettes.
“Most recent works are using implicit methods like encoder-decoder structures which fail to capture the input image’s details. We explicitly estimate 2.5D maps and predict the opposite view of them. This leads to preserving many details from the input image,” paper author Yao Yuan told Synced. Since using 2.5D visible surface geometry as a representation has become a common approach in multi-step 3D reconstruction pipelines, the team also included 2.5D visible surface geometry in their framework.
From raw 2D images with single views, researchers first use a data-driven predictor to compute 2.5D visible surface geometry. This is where the novel Front2Back algorithm comes in. Front2Back employs an image-to-image translation network to predict back view 2.5D visible surface depth and normal maps from the input front 2.5D representation. A final 3D surface reconstruction is then completed once all theses intermediate maps are fused.

Researchers tested the Front2Back method on images from the ShapeNet benchmark dataset, where high quality generated reconstructions showed the effectiveness of the approach. Compared to other learning-based 3D reconstruction methods, Front2Back showed higher accuracy in 9 out of 13 categories.
The paper Front2Back: Single View 3D Shape Reconstruction via Front to Back Prediction is on arXiv.
Journalist: Fangyu Cai | Editor: Michael Sarazen
very good thank you