
We present a method to produce abstractive summaries of long documents that exceed several thousand words via neural abstractive summarization. We perform a simple extractive step before generating a summary, which is then used to condition the transformer language model on relevant information before being tasked with generating a summary. We show that this extractive step significantly improves summarization results. We also show that this approach produces more abstractive summaries compared to prior work that employs a copy mechanism while still achieving higher rouge scores.
Believe it or not the above paper abstract was actually generated by an AI-empowered language model. Researchers from Element AI, MILA (Montréal Institute for Learning Algorithms), and Université de Montréal have introduced a powerful transfer language model that can summarize long scientific articles effectively, outperforming traditional seq2seq approaches.
This work is so impressive it was recommended by Miles Brundage of OpenAI and the Future of Humanity Institute at Oxford University in a tweet that earned 1,170 Retweets and 2,812 Likes in just three days — with one commenter dubbing the model’s convincingly coherent output an “Abstract Turing Test.” So where does this magic fluency come from?
Language models are used to estimate the joint probability of a sequence of words within a larger text. Generally, Markovian assumption — the probability that the next word can be estimated given only the previous k number of words — makes it possible to estimate conditional probabilities for short texts. However, the “curse of dimensionality” will greatly diminish performance on long-range dependencies.
More efficient long term dependencies learning is possible with fully attentive models that use transformer architectures, with logarithmic or constant path length between network inputs and outputs.
Researchers split the abstract summarization task into an extractive step and an abstractive step. The first step ensures that important sentences will be extracted, which can be used to better condition the transformer. The second, abstractive step can thus generate a better summary during the inference phase. The researchers concluded that their extractive step significantly improve the performance of the summarization results.

The researchers choose four large-scale and long document summarization datasets for their experiments — arXiv, PubMed, BigPatent and Newsroom:

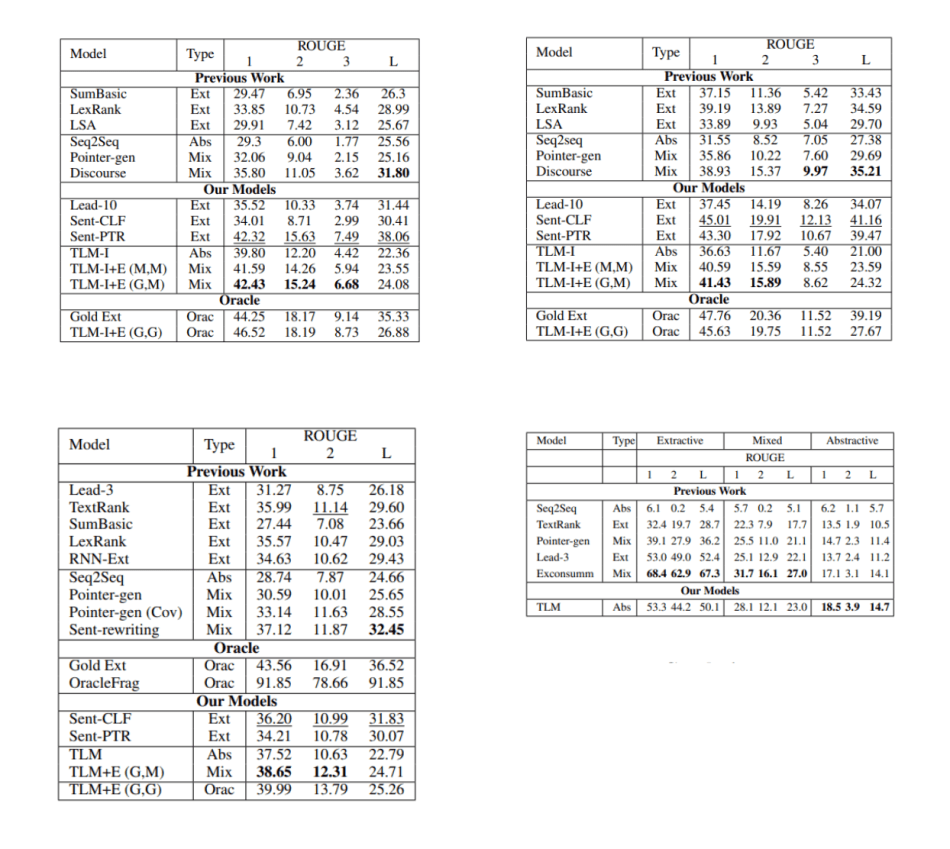
The results show that the new language model outperforms previous extractive and abstractive summarization methods on all training datasets.

The fluency and coherence of the generated example attest to the model’s high performance. It is also noteworthy that the method tends to generate original text content, and is less prone to copying entire phrases or sentences from the training text as previous methods will.
The paper On Extractive and Abstractive Neural Document Summarization with Transformer Language Models is on arXiv.
Author: Hecate He | Editor: Michael Sarazen
0 comments on “Transformer-Based Language Model Writes Abstracts For Scientific Papers”