
No matter whether the conversations commence with “Ok, Google”, “Hello Alexa”, or “Hey Siri”, tech giants Apple, Amazon, Facebook, Google and Microsoft have all granted third-party contractors access to their users’ many interactions with voice assistants.
Voice-controlled IoT services are experiencing unprecedented popularity thanks to advancements in AI technologies such as speech recognition and natural language processing. Voice assistants are deeply integrated into our daily lives, on devices with sophisticated microphone arrays that are ever-listening for wake commands.
Users’ voice data content is sufficiently rich to allow AI systems to build accurate profiles and predictions based on confidence and stress levels, physical condition, age, gender, and even personality. Some online recommendation systems can even provide product or restaurant suggestions based on the speaker’s emotions. But amid rising public concerns that service providers might exploit these insights to violate user privacy, efforts are being made to protect privacy while maintaining the quality and convenience of personalized services.
A team of researchers from Imperial College London has now offered a solution. In the paper Emotionless: Privacy-Preserving Speech Analysis for Voice Assistants, researchers propose adding a privacy-preserving intermediate layer between users and cloud services. They say the method “serves as a wrapper of the emotional part of the voice input to prevent service providers from monitoring users’ emotions associated with their speech.”
In a bid to purge real-time speech data of such sensitive representations before it is shared with service providers, researchers identified sensitive representations in the raw signals, then leveraged voice conversion technology to remove emotion and health state information without damaging other useful indicators. At the heart of the speech analysis approach to learning sensitive representations is CycleGAN, which is responsible for extracting features such as F0 counter, spectral envelope, and aperiodic information. The state-of-the-art vocoder WORLD then uses the output to re-generate the voice files.

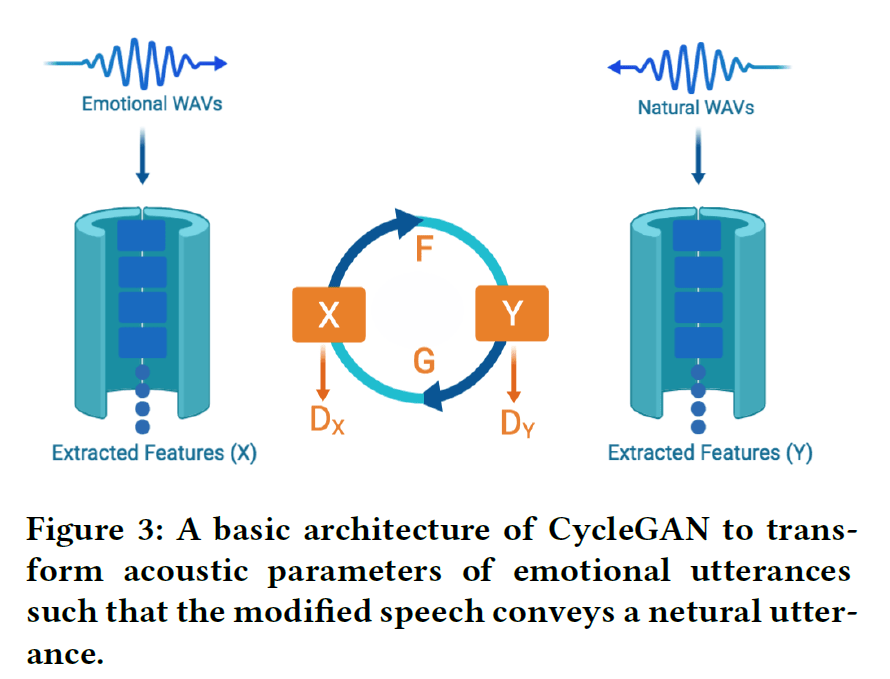
Tests on speech files processed via this method showed a dramatic 96 percent drop in emotion recognition accuracy. This however came with a trade-off, as speech recognition accuracy based on average word error rate correspondingly fell by 35 percent. Researchers suggest these results could be improved by increasing the training epoch.
With today’s intelligent voice systems increasingly capable of not only semantic understanding but also the capture and analysis of sensitive representations, the Imperial College London research presents an interesting new path for preserving privacy without compromising the rapidly growing potential of voice-based human-machine interfaces.
The paper Emotionless: Privacy-Preserving Speech Analysis for Voice Assistants is on arXiv.
Journalist: Fangyu Cai | Editor: Michael Sarazen
The research is quite interesting, but still, it is more pleasant for me to communicate and receive advice from a living person.