
Earlier this year Baidu introduced ERNIE (Enhanced Representation through kNowledge IntEgration), a new knowledge integration language representation model that made waves in the natural language processing (NLP) community by outperforming Google’s BERT (Bidirectional Encoder Representations from Transformers) in various Chinese language tasks.
Today, the research division of the Chinese search giant released their updated ERNIE 2.0, a pretrained language understanding model with significant improvements. The ERNIE 2.0 model outperforms BERT and the recent XLNet (a generalized autoregressive pretraining model) on 16 tasks including English GLUE benchmarks and various Chinese language tasks.
Unsupervised pretrained language models such as BERT, XLNet and ERNIE 1.0 have driven NLP’s widespread uptake, and large-scale pretraining has proven to be of great importance in the growing research field. However, previous pretraining procedures mainly focused on word-level and sentence-level prediction or inference tasks. For example, BERT captures co-occurrence information by combining a masked language model and a next-sentence prediction task; while XLNet captures co-occurrence information by constructing a permutation language model task.
Along with co-occurring information, there is also rich lexical, syntactic and semantic information in training corpora, including named entities, sentence order and sentence proximity information, and semantic similarity and discourse relations among sentences. Unlike traditional pretraining methods, ERNIE 2.0 is built as a continual pretraining framework to continuously gain enhancement on knowledge integration through multi-task learning, enabling it to more fully learn various lexical, syntactic and semantic information through massive data.

Based on this framework, numerous customized tasks can be freely added into ERNIE 2.0 at any time and trained through multi-task learning with the same encoding networks, which enables the encoding of lexical, syntactic, and semantic information across tasks. Notably, ERNIE 2.0 can incrementally train on several new tasks in sequence and accumulate the knowledge it obtains during the learning process to apply to future tasks.

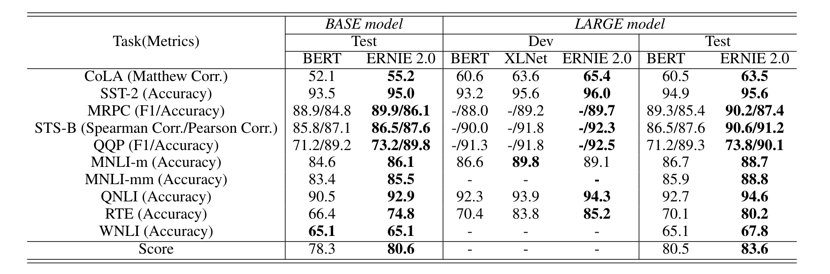
In experiments conducted on single models (instead of ensemble models), ERNIE 2.0 outperformed BERT and XLNet on seven GLUE language understanding tasks. ERNIE 2.0 also beat BERT on all nine Chinese NLP tasks including DuReader Machine Reading Comprehension, Sentiment Analysis, and Question Answering — with its large model achieving SOTA results.

The paper ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding is on arXiv. The ERNIE 2.0 models pretrained on English corpus and its fine-tuned code are now open sourced on Github.
Author: Herin Zhao | Editor: Michael Sarazen; Tony Peng
0 comments on “Baidu’s ERNIE 2.0 Beats BERT and XLNet on NLP Benchmarks”