
In June Synced published an article about Microsoft ObjGAN’s impressive performance on transferring text to images. Now, just weeks later, Carnegie Mellon University researchers have made another leap in the field with their Joint Language-to-Pose (JL2P) model, which generate animations from text input via a joint multimodal space comprising language and poses.
The language-to-pose animation process creates a sequence of poses represented by positions of joints (shoulders, wrists, knees, etc.). The challenge lies in three aspects:
- How to build a latent representation space where language and poses — two significantly different modalities — are mapped together;
- How to stitch different words, which represent different qualities of the animation, into a convincing pose sequence.
- The model is trained under objective metrics while the quality of animation can only be judged by humans. How to correlate these two evaluations.
To tackle these challenges, the CMU researchers had the JL2P model learn a joint embedding of language and pose and optimized it with a progressive training curriculum that helps the model process shorter and easier sequences such as basic leg motions before processing longer and more difficult sequences such as running. The researchers evaluated their model using the following criteria:
- Prediction Accuracy by Joint Space: How accurate is pose prediction from the joint embedding?
- Human Judgment: Which of the generated animations is more representative of the input sentence? Does the subjective evaluation correlate with the results from the objective evaluations?
- Modeling nuanced language concepts: Is the model able to map nuanced concepts such as speed, direction and action in the generated animations?
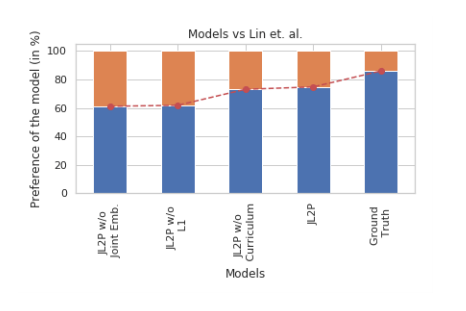
Researchers designed a user study in which human annotators selected the two generated animations they believed most accurately described a specific sentence from a set of six generated animations. Researchers compared the JL2P model’s average positional error results when using different optimizations, and against previous model performance.

The JL2P model showed an improvements of 9 to 15 percent compared to previous models. In the user study JL2P showed scored a 75 percent preference rate, only 10 percent below ground truth. In both the objective metrics and evaluation by humans the JL2P model generated more accurate animations with more reasonable visual representations than other data-driven approaches.
The paper Language2Pose: Natural Language Grounded Pose Forecasting is on arXiv.
Author: Reina Qi Wan | Editor: Michael Sarazen
The raw bar at our american restaurant is a seafood lover’s dream, offering oysters, clams, shrimp, and lobster, all served fresh. For those who want more, the seafood towers provide a grand sampling of the freshest shellfish. The heart of our restaurant success lies in its iconic menu, which is a celebration of American culinary classics.