
In common reinforcement learning (RL) domains, existing keypoint discovery methods struggle to perceive keypoints in an image when there are limited objects present. Transporter, a new architecture recently proposed by DeepMind, enables machines to discover spatially, temporally, and geometrically aligned keypoints even given only a limited amount of data.
Transporter can learn from raw video frames in an unsupervised manner, transporting learned image features between video frames via a “keypoint bottleneck.” The novel architecture tracks keypoints more accurately and more consistently on standard RL domains than other methods.
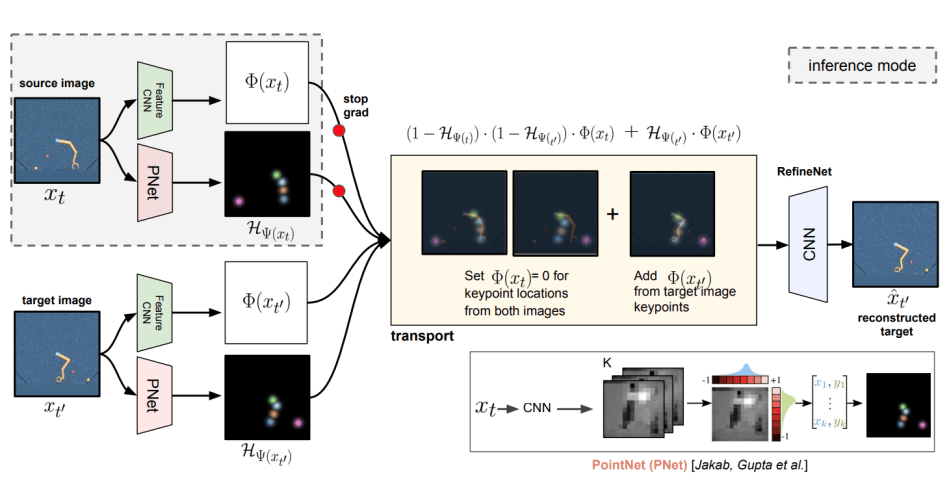
The Transporter model transports image features at the discovered position to extract keypoints by transforming a source video frame (xt) into another target frame (xt0).
As shown above, the Transporter model contains three phases. In the training phase, researchers employ a ConvNet to predict spatial feature maps Φ(xt) and Φ(xt0 ) and a fully differentiable PointNet to predict keypoint co-ordinates Ψ(xt) and Ψ(xt0 ) from video frames. The keypoints are then transformed into Gaussian heat maps.
The training phase is followed by the transport phase which includes two processes: (1) the source frame features are adjusted to zero at both spots HΨ(xt) and HΨ(xt0 ); (2) the source image features at the target positions HΨ(xt0 ) are replaced with the features at the source position HΨ(xt).
The final refinement ConvNet phase has two steps: (1) fill up the missing features at the source position; and (2) wipe out the image around the target positions.

The researchers show that with the novel Transporter architecture it is possible to learn stable object keypoints to provide a flexible representation for efficient control and reinforcement learning, while scaling the keypoints for larger datasets and environments. Tracking objects over long temporal sequences could also help inform learning policies by learning object dynamics and affordances.
Transporter remains robust with varying object(s) number, size, and motion, and the experiment results show that using learned keypoints as input leads to better performance compared to existing methods on several Atari environments with fewer than 100k environment interactions.
The paper Unsupervised Learning of Object Keypoints for Perception and Controlis on arXiv.
Author: Hongxi Li | Editor: Michael Sarazen
0 comments on “DeepMind Transporter: Unsupervised Learning of Object Keypoints”