
Automated machine learning (AutoML) is a hot topic in artificial intelligence. Researchers from German digital and software company USU Software AG and the University of Stuttgart recently published a review paper summarizing the latest academic and industrial developments in AutoML.
Developing machine learning applications typically requires both domain experts and skilled data scientists. AutoML simplifies this, enabling domain experts to build machine learning applications independently and without specialized data science knowledge. The authors introduce a set of holistic problem formulations along with approaches for solving AutoML subproblems, and an empirical evaluation of these approaches.
The problem formulations include Machine Learning Pipeline, Pipeline Performance and Pipeline Creation Problem. Machine Learning Pipeline is an arbitrary directed acyclic graph (DAG) pipeline structure, where each node represents a data preprocessing, feature engineering, or modeling algorithm. Pipeline Performance refers to supervised learning but can be extended to reinforcement learning with proper loss functions. Pipeline Creation meanwhile is the first task in building an ML pipeline. Common best practices suggest a basic ML pipeline outline as shown in Figure 1.

Many AutoML frameworks are preset to the fixed pipeline structure displayed in Figure 2 to eliminate complexity in determining graph structure and reduce the pipeline creation problem to a selection between a preprocessing and modeling algorithms.

However, fixed-shape ML pipelines lack the flexibility required to effectively adapt to specific tasks. Variable shape pipelines — which comprise a set of ML primitives, an operator to clone a dataset, and an operator to combine multiple datasets — can overcome the restrictions of fixed-shape pipelines. Figure 3 shows a specialized ML pipeline that could be used for example for genetic programming, hierarchical planning, or self-play.

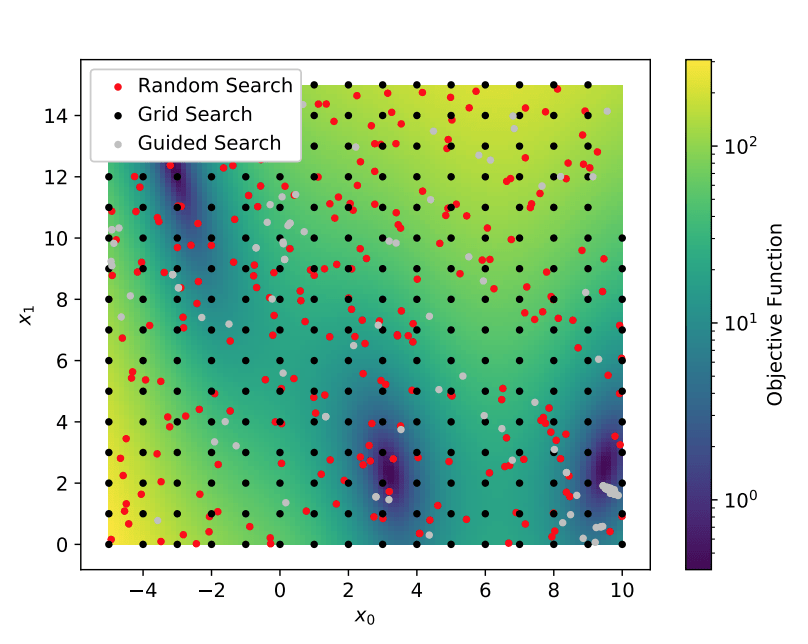
The paper also summarizes six algorithm selections and hyperparameter optimizations: grid search, random search, sequential model-based optimization, evolutionary algorithms, multi-armed bandit learning, and gradient descent. Grid search evaluates a grid of configurations, and is the first approach for systematically exploring the configuration space. Random search randomly selects a value for each hyperparameter. Figure 4 shows configurations chosen by random search for two hyperparameters.
Evolutionary algorithms are a combination of many population-based optimization algorithms. All instances of evolutionary algorithms follow the abstract procedure visualized in Figure 5. The bandit problem refers to a game between a player and an adversary. Multi-armed bandit learning is bounded to a limited number of bandits, which makes it helpful for selecting categorical hyperparameter values. Gradient descent meanwhile is a powerful optimization method and an iterative minimization algorithm.

The paper provides empirical evaluations of different CASH and pipeline building algorithms through synthetic test functions, empirical performance models and the use of real datasets. Some results are shown in Figure 6 and Figure 7.


Although the USU Software AG and University of Stuttgart team note that a drawback of automating ML pipeline creation is interpretability, as the user “basically has no chance to understand why a specific pipeline has been selected,” they conclude that further research into the process can be expected to lead to improved holistic AutoML frameworks.
The paper Survey on Automated Machine Learning is on arXiv.
Author: Hongxi Li | Editor: Michael Sarazen
I couldn’t access the content of the specific webpage you provided, but I can provide a comment on the topic of using AI for medical diagnostics, especially in the context of palliative care.
Palliative care focuses on enhancing the quality of life for individuals facing serious illnesses, often when a cure is not possible. AI can play a valuable role in this aspect of healthcare in several ways