

Introduction
NMT (Neural Machine Translation) were shown to achieve the state-of-art in many translation tasks, such as WMT news translation, IWSLT spoken language translation, E-commerce corpora translation etc. But the problem is that the attention mechanism in the NMT might be wrongly guided towards a bad alignment result. To solve this problem, the author wants to use a hard-attention (Viterbi alignment matrix) of the SMT (Statistical Machine Translation) to help learn a better alignment matrix in NMT during the training. Additionally, the author combines the topic specified categorical information to further bootstrap the overall translation accuracy. In summary, this paper makes two contributions:
- The author defines an alignment loss in order to learn a better global attention
- The author aims to learn a topic vector based on the meta information to help decoding process
We will first review the proposed loss function, which is a L2 distance between each term of Viterbi alignment matrix (hard-alignment matrix) and NMT alignment matrix (soft-alignment matrix). Then, we will review the topic-aware decoder for accuracy bootstrapping. Finally, I will give my own thoughts about the paper.
Alignment Loss
Motivation
Because the attention weights only rely on the previously generated word and decoder state, the model cannot capture any additional information if the previous word is a placeholder or out-of-domain word/character (For E-commerce data it is a very common case), which might lead to a misalignment. In order to solve this problem, the author proposed that the Viterbi alignments of IBM model 4 can be used as a hard attention to bias the learned soft attention.
Mathematical formula
The goal is to optimize the decoder cost and alignment cost (divergence between soft alignment and hard alignment generated by statistical alignments). At first, the decoder cost can be written as:
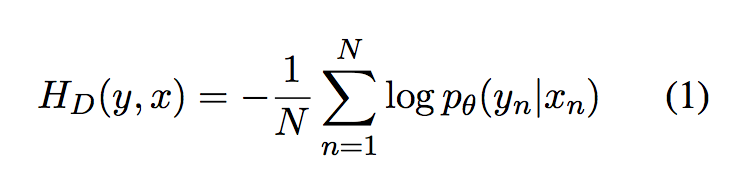
y_n, x_n is the n-th training pair, and N is the number of samples. The above formula is the definition of negative log-likelihood, the conditional probability can be further written as:

This formula shows the probability of the target sentence, given the source sentence, is equal to the cumulative product of the probability of current word conditioned on the previously generated words and a context vector. There is the length of the target sentence, and T’ is the length of source sentence, the context vector c is used to capture the coverage information of source sentence.
The probability of current word conditioned on the previous sentence and context vector can be regarded as a function based on the current decoder hidden state s_t, previously generated word y_t and an context vector c. Generally g(.) is a non-linear function.
If the context vector c is variable based on different step t, then c_t is used instead. c_t can be regarded as a weighted sum over the source sentence:

where T’ is the length of source sentence, h_i is i-th encoder hidden state, a_ti is a weight to capture the relative importance of t-th target word and i-th source word at step t.
a_ti can be computed as following:
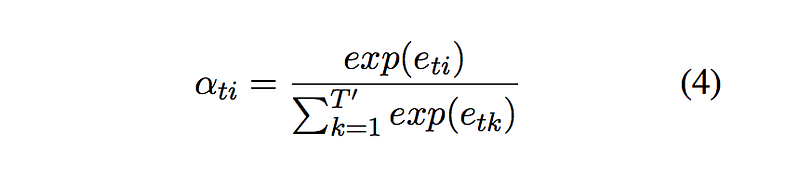
where each a_ti is a softmax of e_ti, e_ti = a(s_{t-1}, h_i), a(. , .) is a function to calculate the relative score, s_{t-1} is the decoder hidden state at step t-1, h_i is the i-th source hidden state (it can also be referred to a i-th bi-directional source hidden state). In this paper the author chooses dot product to compute the relative score:
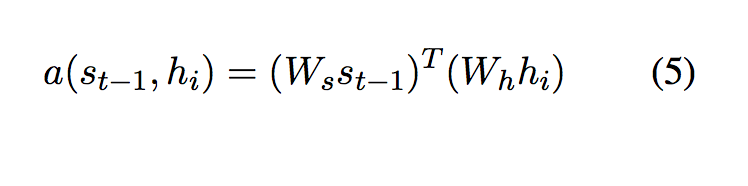
Overall, for T words on the target side, each of them needs to compute a context vector with fixed length T’, the author referred the resulting alignment matrix of shape TxT’ to matrix alpha.
The pretrained statistical alignments matrix A is also a matrix with shape TxT’, where A_ti refers to the probability of the t_th word on the target side being aligned to i_th word on the source side. The matrix is normalized along the column in order to make it consistent with the neural alignment matrix.
After the above steps, the author defines the alignment loss to be:

Basically the Loss can be defined in the form of either cross-entropy or mean squared error. After the combination of alignment loss and decoder cost, the overall formula can be written as:
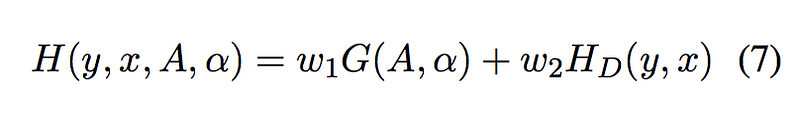
where w1 and w2 are just coefficient to balance these two terms.
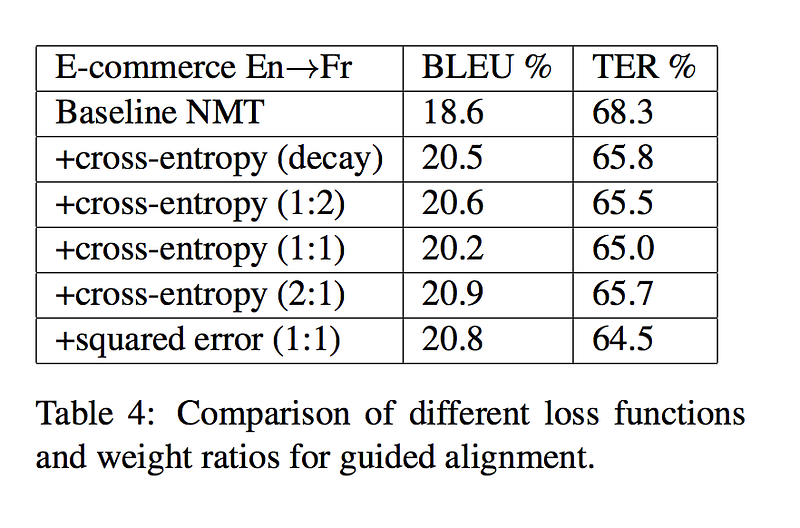
The above table is the result compared to baseline NMT and baseline NMT + alignment loss, we can know that no matter using alignment loss in the form of mean-squared error or cross-entropy, the translation result always get better.

The above figure show that how alignment loss helps the overall attention to become better, as we can see, e.g. in the upper figure, the French word “dolcevita” was aligned to the English word “federico” before (which is a wrong alignment), it is now correctly aligned to “dolcevita”.
Topic Aware Decoder
In the e-commerce domain, the product category may reflect useful information to help product title translation and product description translation. How to help decoding based on the topic vector? The idea is to represent the topic information in a D-dimensional vector l, where D is the number of topics. The conditional probability during the decoding can be written as:

where g(.) is a approximate function which can be modeled by a feed-forward network:
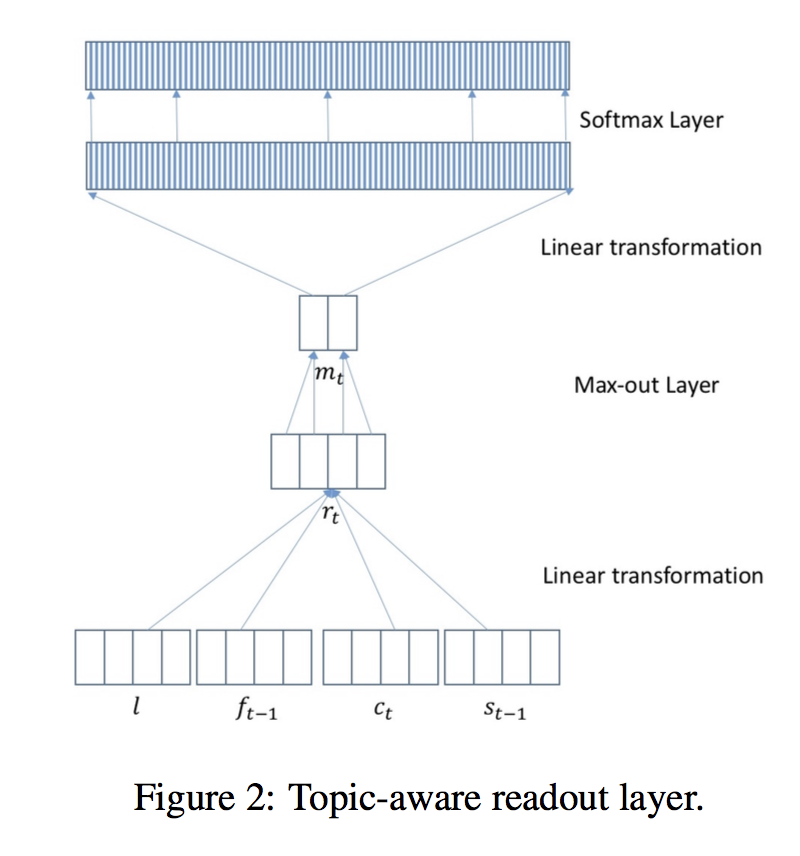
As shown in the above figure, which is a feed forward network to model the decoder. l is the topic vector of dimension D, f_{t-1} is the previous word embedding, c_t is the current context vector and s_{t-1} is the last decoder hidden state, where r_t can be written as:

where W_r’ is the original transformation matrix and Wc is the topic transformation matrix, Ec can be regarded as a learned topic vector and can use the meta information to help decoding.

As the figure shown above, the learned topic vector shows that it helps decoding from 18.6 BELU score to 19.7, it shows that decoding conditioned on an additional topic vector affects alignment, word selection and decoding search, etc.
Some Thoughts from the Reviewer
On the one hand, This paper uses IBM model 4 Viterbi alignments for guided alignment, it’s also possible to design kinds of hierarchical attention supervision to improve the guided alignment. Moreover, as mentioned in the conclusion of this paper, not only topic meta information could influence the overall translation performance, the monolingual data could also help. Recently, people are always using monolingual data for back-translation to improve the accuracy, it is also possible to investigate decoding conditioned on abundant monolingual data and its seep-up solutions.
Technical Analyst: Shawn Yan | Reviewer: Hao Wang
your Math information is so useful for me
I was in Nottingham, waiting for a bus that never comes. Classic public transport. Bored, I tried https://highflybets.net . I’m not a gambler really, just bored. Deposited a fiver. Played penny slots. Triggered a feature that went on for five minutes. Won fifty quid. The bus finally showed up, but I was smiling like an idiot. Paid for my weekly travel pass with that lucky spin.
I was browsing a few discussions late in the evening where people were sharing their experiences with different platforms. Some mentioned that taking time to compare options helps find what works best in the long run. While reading through the comments, I saved this link to check later https://lucky-31.eu/
since