
Event Information/ Video Source:
Speaker: David Silver, Google DeepMind
http://techtalks.tv/talks/deep-reinforcement-learning/62360/
Intro & Abstract:
Reinforcement Learning (RL) is becoming increasingly popular among relevant researchers, especially after DeepMind’s acquisition by Google and its subsequent success in AlphaGo. Here, I will review a lecture by David Silver, who is currently working at Google DeepMind. It’s not very difficult to understand, and I think it can help us acquire a basic understanding of RL or Deep RL.
In this video, David will give a basic introduction to Deep Learning (DL) and Reinforcement Learning (RL) , as well as discussing how the two can be combined into one approach. There are three ways to combine DL and RL, based on three different principles: value-based, policy-based, and model-based approaches with planning. During this lecture, David provided many examples of their experiments, ending with a brief discussion about AlphaGo.
Overview
This lecture is divided into 5 sections:
- Introduction to Deep Learning
- Introduction to Reinforcement Learning
- Value-Based Deep RL
- Policy-Based Deep RL
- Model-Based Deep RL
However, after taking finishing the lecture and going through the topics, I decided to introduce an additional section to first provide an overview of Deep RL. This article will be organized as below:
- Introduction to Deep Learning
- Introduction to Reinforcement Learning
- Deep Reinforcement Learning
- Value-Based Deep RL
- Policy-Based Deep RL
- Model-Based Deep RL
Hopefully, this structure will help you to better understand the whole topic. I will focus on the key points of this video, and try my best to explain the complicated concepts for some of the problems. I will also offer my own opinions, suggestions and some references which hopefully can help you.
Because it might be quite difficult for people who don’t have a basic understanding of DL and RL to understand this lecture. Before the diving into the more complex RL topics, I will try my best to provide some basic knowledge in these two topics. Hopefully this will help you. If you feel confident in your knowledge, you can skip the first 2 sections.
Introduction to Deep Learning
What is Deep Learning?
DL is a general-purpose framework for representation learning:
- Given an objective
- Learn representation that is required to achieve objective
- Directly from raw inputs
- Using minimal domain knowledge
The meaning of deep learning is deep representations.

The degree of “deep” can be inferred from the number of functions (parameters). The reason behind deep learning’s sudden popularity in the last few years is due to the development of computer hardware and algorithms which can compute these function in an appropriate period.
Backpropagation algorithm plays an essential role in solving deep problems. It is important for anyone who wish to learn machine learning to understand backpropagation.
Don’t get Deep Neural Network and Deep learning mixed up. Deep Learning is a technique for implementing machine learning. [3] It is just one of method of Machine Learning. Deep Neural Networks, on the other hand, are typically used by people to understand deep representation.

We training Neural Networks by Stochastic Gradient Descent

A very effective technique in practice is Weight Sharing, which is the key to reduce the number of parameters. And we have two kinds of neural networks which can implement weight sharing. The Recurrent Neural Network, and the Convolutional Neural Network.

Introduction to Reinforcement Learning
What is Reinforcement Learning?
In this lecture, David gave us a graph which indicates the complicated location of RL among different fields.

Although we use RL extensively in the Machine Learning community, RL is not only an Artificial Intelligence terminology. It is a central idea among many fields, hence the slide title “Many Face of Reinforcement Learning”. In fact, many of these fields are faced with the same problem as machine learning: how can we optimize decisions to achieve the best result.
It’s the science of decision-making. In neuroscience, people study human brains and found a reward system which follows well-known reinforcement algorithms. In psychology , people studied classical/operant conditioning, which we can also think of as a reinforcement problem. Similarly, in economics people studied Rationality Game Theory; in mathematics people studied Operations Research; in engineering people studied Optimal Control. All of these problem can be considered as a Reinforcement Learning problem – they are studying the same question, to optimize decision-making to achieve the best result.
Reinforcement learning is an area of machine learning inspired by behaviorist psychology [4]. Take a student Mike for example. If he read a paper about RL, then he gets +1 grade today + the grade he got yesterday (called positive feedback). He will get -1 grade if he plays basketball all day. Therefore, as Mike will try to get more rewards every day (positive feedback), he will study every day.
“In an essential way these are closed-loop problems because the learning system’s actions influence its later inputs. Moreover, the learner is not (1)told which actions to take, as in many forms of machine learning, but instead must (2)discover which actions yield the most reward by trying them out. In the most interesting and challenging cases, (3)actions may affect not only the immediate reward but also the next situation and, through that, all subsequent rewards. These three characteristics—being closed-loop in an essential way, not having direct instructions as to what actions to take, and where the consequences of actions, including reward signals, play out over extended time periods—are the three most important distinguishing features of the reinforcement learning problem.” [2]
Reinforcement learning differs from standard supervised learning in that correct input/output pairs are never presented, nor sub-optimal actions explicitly corrected. Furthermore, there is a focus on on-line performance, which involves finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge) [4].
We introduced RL before:
And a video demo: https://www.youtube.com/watch?v=V1eYniJ0Rnk
So why should we care about RL? In a nutshell, RL is a general-purpose framework for decision-making. What we actually care about is to build an agent which can act in the real world. We don’t just want give them an algorithm and take actions. We want them to make decisions. And RL can let an agent learn how to make decisions.
- RL is for an agent with the capacity to act
- Each action influences the agent’s future state
- Success is measured by a scalar reward signal
- Goal: select actions to maximize future reward

Since every problem has their own, different characteristics, in order to achieve “general purpose”, we need to find their common and formal things. Hopefully, you can understand the slide above without explanation. The brain is the agent here, and the world is the environment. Whenever the agent executes an action at, the agent will receive observation ot and scalar reward rt; the environment emits observation ot+1 and a scalar reward rt+1 after it receives at . This introduces a new concept: state.

The slide above shows that the state is a summary of experiences (first function). However, if the environment has a property which we call fully observed, then we get the second function.
Then there are three new ideas: Policy, Value function, and Model.


Value Function:

The Bellman equation, named after its discoverer Richard Bellman (also known as the dynamic programming equation) is a necessary condition for optimality associated with the mathematical optimization method known as dynamic programming [5].

Model:

Since we have identified the three components of a RL agent, it is easy to understand that optimizing any one of them will yield a better result.

Deep Reinforcement Learning
What is Deep Reinforcement Learning? In short: RL + DL
We are bringing two things together: we seek a single agent which can solve any human-level task, RL defines the objective and DL gives the mechanism, the way to represent problems, and the way to solve the problems. RL plus DL yields general intelligence – the ability to solve many complex problems.
Examples of Deep RL at DeepMind:
- Play games: Atari, poker, Go
- Explore worlds: 3D worlds, Labyrinth
- Control physical systems: manipulate, walk, swim
- Interact with users: recommend, optimize, personalize
So how can we combine RL and DL?
- Use deep neural networks to represent
- Value function
- Policy
- Model
- Optimize loss function by stochastic gradient descent.
In the following three sections, we will discuss three method to combine RL and DL.
Value-Based Deep RL
The fundamental idea of a Value-Based Deep RL is to build a representation of the value function, which we will call a Q-Network Function.

Where:
- s = states
- a = actions
- w = weights
As we can see from the slide above, we basically get a black box which takes input s and a, and spits out output Q and some parameter w
The fundamental approach we’re going to use is based on Q learning. This is a way to come up with the lost function we need, and we’ll start with the Bellman equation.

We treat the right hand side as a target, and we’re going to say with each iteration of this algorithm, just move the left hand side towards the right hand side. Basically, we treat the right hand side as the desired property we want (follow function).

We then minimize MSE loss using stochastic gradient descent (as we can see from the slide) and it works. If we have a separate value for each state and each action, this converges to the optimal value function. Unfortunately because we use neural networks here, there are two problems:
- The correlations between the samples: Say if I’m a robot wondering around, and I’m learning from the actual data. I treat each step of the algorithm as states taking actions, and theses states and actions are very similar to the last action performed. There is a very strong correlations along the path that we follow.
- These targets we’re learning from depend on themselves, such that these are non-stationary dynamics. Because there are no stationary dynamics, our function approximation will spiral out of control and cause our algorithm to go crazy.
These two problems cannot be solved if we continue using neural networks.
The first algorithm we introduced for stable Deep Reinforcement Learning was called DQN. As the slide below demonstrates, this introduced a fundamental improvement over the basic Q- learning algorithm. The idea here is very simple: remove all the correlations in this non-stationarity, building the data-set from the agent’s own experience. Then sample experiences from the data-set and apply update.
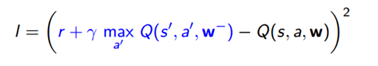

After the above explanation, Silver gives us an example from DeepMind: Atari. They train a system to play Atari game swell. And I think the graph is quite helpful for readers to understand the relationship between the agent and the environment (including state, action and reward).

DQN in Atari:
- End-to-End learning of values Q(s,a) from pixels s.
- Input state s is stack of raw pixels from last 4 frames
- Output is Q(s,a) for 18 joystick/button positions
- Reward is change in score for that step

(This is a CNN)
Network architecture and hyperparameters fixed across all games
DQN Atari Demo:
- DQN paper: www.nature.com/articles/nature14236
- DQN source code: sites.google.com/a/deepmind.com/dqn/
- We also introduced DQN before: http://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650716425&idx=1&sn=bf52c653b7cd054ce721ce5be928c623&scene=21#wechat_redirect
There have been many different improvements after they published DQN on Nature, but David just focused on three here:

Double DQN:
To understand the first improvement, we first have to understand that there is a problem with Q-learning. The problems come with the MAX operator. The approximate value is actually not good enough to make a decision and this bias may cause a serious problems in practice. Therefore, to solve this problem, we use two DQN to decompose the way that we evaluate our actions into two paths. One is used to select actions and the other one is used to evaluate actions, which really helps in practice.
Prioritized Replay:
The second improvement is the way we do replay. The old method to do replay was using it like an uniform weighting of experiences. But uniform isn’t a great idea, and you can do much better if you prioritize your experiments. We just take the absolute value of that error, which indicates how surprising or how wrong you are in that particular state at the moment. Those experiences are the ones you want to run over the most, because they’re the ones that you really don’t understand very well. You need to get more updates in order to correct your key values.
Dueling Network:
The third improvement is just splitting a Q-network into two channels. One part of it computes how much value you can get if you ignore actions (action-independent in slide). The other part computes how well you can do if you actually take a particular action (action-dependent in slide). Then take the sum of the two. If you normalize this thing, it turns out that these two channels will be glittering because they have such different scaling properties (as demonstrated in the video before). It’s actually more helpful to separate the two to help our neural network learn more.
They sped up their system by using the following structure in Google, which is suitable for large amounts of data.

This structures works over many different machines, where they communicate to run that DQN algorithm together. We have many instances of our agents acting in parallel, with many different instances of our environment, on many different machines, generating as much experience as power allowed us to.
These experiences gets stored into a distributed experience replay memory. Essentially gathering all the experiences of these guys and storing it in a distributed way. We have many learners sampling those experiences in parallel. Once you have this experience replay buffer, we can have many different things all reading from it and applying updates. Then the parameter updates coming back from those learners will be shared into our stored distributed neural network, and then be shared among each of the things actually running across these machines.
How can we speed up RL without resource from google? Asynchronous Reinforcement Learning:
- Exploits multithreading of standard CPU
- Execute many instances of agent in parallel
- Network parameters shared between threads
- Parallelism decorrelates data
- Viable alternative to experience replay
- Similar speedup to Gorila – on a single machine!
Policy-Based Deep RL




A3C in Labyrinth

- End-to-end learning of softmax policy π(a|st) from pixels
- Observations ot are raw pixels from current frame
- States st = f(o1, …, ot) is a recurrent neural network (LSTM)
- Outputs both value V(s) and softmax over action π(a|s)
- Task is to collect apples (+1 reward) and escape (+10 reward)
Asynchronous Methods for Deep Reinforcement Learning Demo: Labyrinth
https://www.youtube.com/watch?v=nMR5mjCFZCw&feature=youtu.be
How can we deal with high-dimensional continuous action spaces?

Similar to DQN, we have DPG here. Hopefully, by now you have a good understanding of DQN, which will be helpful for you in the next section. (Deterministic Policy Gradient Algorithms, http://www.jmlr.org/proceedings/papers/v32/silver14.pdf)

DPG in Simulated Physics
- Physics domains are simulated in MuJoCo
- End-to-end learning of control policy from raw pixels s
- Input state s is stack of raw pixels from last 4 frames
- Two separate convnets are used for Q and π
- Policy π is adjusted in direction that most improves Q

We then looked at other classical games, like poker. Can we use deep reinforcement learning to find Nash equilibrium in multi-agent games? Nash equilibrium is like the solution to the multi-agent decision making problem. At this equilibrium, each agent is happy with their policy, and no agent wishes to deviate from that policy. Therefore, if we find the Nash equilibrium, then we sort of solved the small problem. Lots of research is focusing on how to achieve this in larger, more interesting games.
The idea here is that we’re going to first learn a Q-network, then learn a policy network, then pick actions between “best response” and “average of best response”.

The slide below demonstrates the result of FSP in Texas Hold’em Poker: as the iteration increases, the different algorithms converges.

Model-Based Deep RL
Learning Models of the Environment
- Demo: generative model of Atari
- Challenging to plan due to compounding errors
- Errors in the transition model compounded over the trajectory
- Planning trajectories differ from executed trajectories
- At end of long, unusual trajectory, rewards are totally wrong
Learning a model (how to do model-based reinforcement learning using deep learning) is not the hard part of this problem. We know how to formulate the problem of learning a model. This is really just a supervised learning problem(if you want to predict what the environment will be if I take an action or what will I see next). In this lecture he didn’t talk about this question too much, he just showed a video from the University of Michigan to demonstrate how well you can build a model and how hard is it. This is a screenshot of that video: On the left is the prediction and on the right is the real situation. But this was very difficult to achieve.

However, what if we have a perfect model? E.g. game rules are known. Yes, we know AlphaGo.
AlphaGo paper: www.nature.come/articles/nature16961
AlphaGo resources: deepmind.com/alphago/

Why is Go hard for computers to play?
Game tree complexity = b d. Brute force search intractable:
- Search space is huge
- “Impossible” for computers to evaluate who is winning (In some games like chess it is easy to know the specific winner)
Many people thought it is impossible to find a good way to solve this problem effectively.
DeepMind built a CNN, and sees each state (whenever a stone is put down) as an image. Then used it to build two different neural networks:
One represents the value network

The other represents the policy network

To train this, we combine forces from both supervised learning and reinforcement learning as follows (3 training processes).

The performance after each procedure:



The effect of value network and policy network:



In conclusion
- General, stable and scalable RL is now possible
- Using deep networks to represent value, policy, model
- Successful in Atari, Labyrinth, Physics, Poker, Go
- Using a variety of deep RL paradigms
RL is an area of machine learning inspired by behaviorist psychology. It is becoming increasingly popular, and is quite useful when building an AI to do things more like a human or even better than humans (such as AlphaGo). However, from my perspective, before we start learning RL, we should first understand some basic machine learning knowledge. A good mathematics background will be very helpful for your studying. That, and remain critical.
Good luck, and I hope to see your paper in next ICML.
Reference and Suggested Reading
- http://videolectures.net/rldm2015_silver_reinforcement_learning/
- Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. Vol. 1. No. 1. Cambridge: MIT press, 1998.
- https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
- https://en.wikipedia.org/wiki/Reinforcement_learning
- https://en.wikipedia.org/wiki/Bellman_equation
- https://devblogs.nvidia.com/parallelforall/deep-learning-nutshell-reinforcement-learning/
Analyst: Duke Lee | Editor: Arac Wu | Localized by Synced Global Team : Xiang Chen
0 comments on “David Silver, Google DeepMind: Deep Reinforcement Learning”