
In February, Microsoft introduced its open-source deep learning training optimization library DeepSpeed with memory optimization technology ZeRO (Zero Redundancy Optimizer), which helped build the 17-billion-parameter Turing Natural Language Generation model (T-NLG). In step with its AI at Scale initiative, Microsoft has now released four additional DeepSpeed technologies to enable even faster training times, whether on supercomputers or a single GPU.

3D parallelism is a combination of three parallelism approaches — ZeRO-powered data parallelism (ZeRO-DP), pipeline parallelism, and tensor-slicing model parallelism — that adapts to the varying needs of workload requirements while achieving “near-perfect memory-scaling and throughput-scaling efficiency.” The new feature allows DeepSpeed to train a language model with one trillionparameters using as few as 800 NVIDIA V100 GPUs.

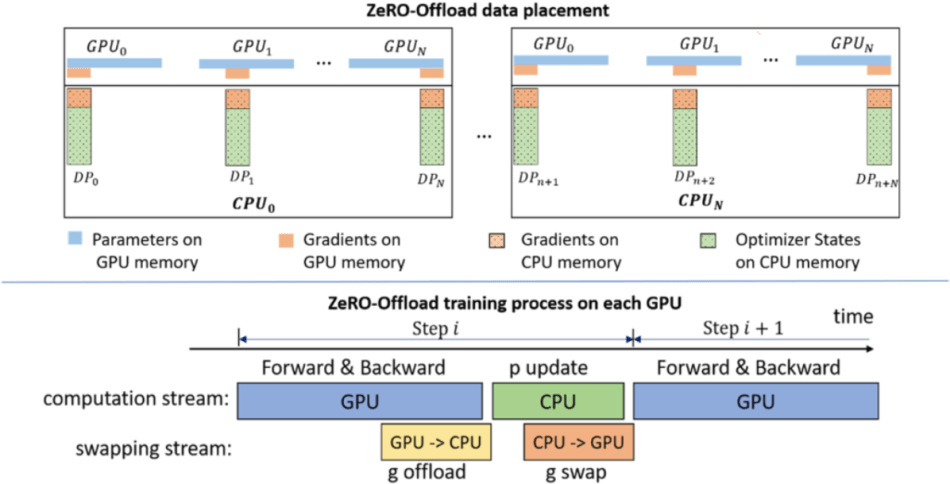
The second DeepSpeed add-on, ZeRO-Offload, exploits computational and memory resources on both GPUs and their host CPUs, and will be of interest to deep learning practitioners with limited GPU resources. The key technology behind ZeRO-Offload is ZeRO-2, which offloads optimizer states and gradients onto CPU memory to enable a single NVIDIA V100 GPU to train models with up to 13-billion-parameter — 10x larger than the current state-of-the-art.
The new Sparse Attention (SA) kernels technology meanwhile addresses the limitations of compute and memory requirements in applying attention-based deep learning models. SA can reduce the quadratically growing compute and memory requirements via block-sparse computation, empowering 10x and 16x longer sequences compared with dense BERT-Base and BERT-Large, respectively. SA can also train up to 6.3x faster for BERT-Base and 5.3x for BERT-Large.

The last advancement is a 1-bit Adam Optimizer, which uses preconditioning to address error compensation compression techniques that do not work with non-linear gradient-based optimizers such as Adam. The compression stage of the algorithm is controlled by a threshold parameter — when changes in variance fall below a certain threshold, it switches to the compression stage. 1-bit Adam offers the same convergence as Adam, but incurs up to 5x less communication — enabling up to 3.5x higher throughput for BERT-Large pretraining and up to 2.7x higher throughput for SQuAD fine-tuning.
The Microsoft Blog post is here, and the codes, tutorials and documentations have been open-sourced on GitHub.
Analyst: Reina Qi Wan | Editor: Michael Sarazen; Fangyu Cai

Synced Report | A Survey of China’s Artificial Intelligence Solutions in Response to the COVID-19 Pandemic — 87 Case Studies from 700+ AI Vendors
This report offers a look at how China has leveraged artificial intelligence technologies in the battle against COVID-19. It is also available on Amazon Kindle. Along with this report, we also introduced a database covering additional 1428 artificial intelligence solutions from 12 pandemic scenarios.
Click here to find more reports from us.

We know you don’t want to miss any latest news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: Microsoft Democratizes DeepSpeed With Four New Technologies – IAM Network
I hosted my daughter’s birthday party at PJ Clarke’s in Lincoln Square, and it was an unforgettable experience! The private dining room was beautifully decorated and provided the perfect setting for our celebration. We opted for a selection of dishes from the menu, and they were all amazing. If you’re looking for a great venue, click here to check out their offerings!
Microsoft’s DeepSpeed updates significantly lower the hardware barrier for massive AI models by introducing 3D parallelism, CPU offloading, sparse attention, and communication-efficient optimization EmpowerRetirement