
Head image courtesy Sandbox Studio
Making science accessible for all is a wonderful and enriching proposal. Unfortunately the execution is not that easy — and nobody knows this better than the team that pioneered arXiv, the world’s largest free scientific paper repository.
Launched in 1991, arXiv has become an indispensable platform providing free and open access to research for the machine learning community and beyond. Now, arXiv has announced plans to alpha test its next-generation “arXiv-NG” submission system in the first quarter of 2020. The system is a significant part of the growing arXiv-NG initiative that aims to improve core service infrastructure through an incremental and modular renewal of the existing arXiv system.
The arXiv team has already taken the initial steps to improve the overall accessibility of the repository’s user interfaces, both through behind-the-scenes structural improvements and user-facing changes — adding for example support for mobile-friendly abstract pages.
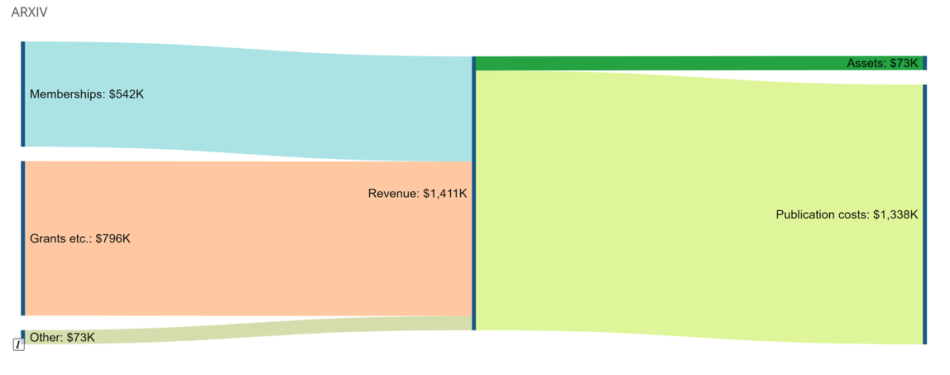
ArXiv is a private and not-for-profit educational institution owned and operated by Cornell University with funding from Cornell, the Simons Foundation and other member institutions. In 2019, arXiv received 155,866 paper submissions — an 11 percent increase from 2018 — and saw about 260 million global downloads.
Despite its relatively small target audience, scientific publishing is a very lucrative business dominated by a tight circle of subscription-based journals. The Guardian reported in 2017 the industry generated total global revenue of more than £19 billion (US$24.3 billion). For years, publishing in a respected scientific journal was the only way for scientists to get their new research out there — but many have grown increasingly critical of a system they believes both profits from and restricts access to their work.
The machine learning community is the forefront of an ongoing movement for free and open access publishing. Last March the University of California system halted all further subscriptions with Elsevier, one of the world’s largest scholarly publishers, after failing to reach an agreement on securing universal open access for UC research on the platform. The move was applauded by Turing Award winner and Facebook Chief AI Scientist Yann LeCun on Facebook.
ArXiv’s expenses for 2019 totalled only around US$2 million — a ridiculously low price for the value. But is such an open-access publishing scheme sustainable? A tweet from University of Glasgow human-computer interaction lecturer and VP of Publications at ACM SIGCHI Julie Williamson warns the costs per paper may escalate as arXiv enters this new NG phase.
Williamson recently published an article on the ACM SIGCHI website that looks into the economics of open access publishing. The ACM SIGCHI (Association for Computing Machinery’s Special Interest Group on Computer Human Interaction) is an international society for professionals, academics and students interested in human-computer interaction.
Many of the papers published by non-profit organizations like the ACM and IEEE are put behind paywalls. Williams says the ACM could transition to universal gold open access and make all content in the ACM Digital Library freely available, but certain tradeoffs would have to be made in order to do that.
University of San Francisco research scientist Jeremy Howard also tweeted on the topic — noting that while arXiv handles its high submissions and downloads for just a couple of million dollars, the ACM spends $10 million on publications, and IEEE spends $193 million — “something stinks.”


There are significant costs involved in scientific publishing, even for non-profit publishers: software, storage, bandwidth, and professional staff, etc. Williamson suggests arXiv costs are so low because the repository spends much less on visual standards, metadata standards, and other long-term and strategic work. But is there more to it?
Unlike arXiv, ACM and IEEE are scholarly societies, which Williamson stresses “sustain important community activities by reinvesting revenue from various sources including publishing.” She also replied to Howard on Twitter that “ACM should not become arXiv, and vice versa, there is a place for both immediate dissemination and prestigious dissemination.”
The ACM and IEEE also conduct a wide range of activities apart from publishing — such as conferences, standards development, career development, education and policy work and so on. These activities incur additional financial and legal responsibilities for the organizations.
As non-profit publishers, these organizations generate revenue that roughly covers operating costs and a surplus that’s either held as assets or reinvested in the community. They may have to choose between providing free and open access papers or supporting community activities such as conferences, student travel grants, career development events, etc.
Williamson proposes a number of ways these organizations might find the funds to support universal open access. One would be to increase conference fees. Another is to cut community initiatives that are not economically self-sustaining, such as student travel grants, regional development activities, and educational events. Williamson says an ideal solution would be attracting additional philanthropic donations to support open access.
At this point it would seem that although scholarly societies acknowledge the importance of and demand for open access, they remain reluctant to abandon the revenues generated by their traditional subscription models and financial structures.
Journalist: Yuan Yuan | Editor: Michael Sarazen
It’s worth highlighting that ArXiv is a pre-print server so does not have all the costs associated with running full peer review – Open Access or otherwise. To say that Arxiv is an example of low cost Open Access is misleading. Open Access Peer Review and Open access pre-print are very different things.
Thank you very much.