
The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) opened on August 4 in Anchorage, Alaska. KDD 2019 features both a Research track and an Applied Data Science (ADS) track, and today organizers announced their Best Paper Awards. A Cornell University research team took top honours in the research track for Network Density of States; while in the ADS track the winner was Actions Speak Louder than Goals: Valuing Player Actions in Soccer, from researchers at Katholieke Universiteit Leuven and SciSports.
Best Paper Award – Research Track
Network Density of States
Cornell University
Kun Dong, Austin R. Benson, David Bindel
Abstract: Spectral analysis connects graph structure to the eigenvalues and eigenvectors of associated matrices. Much of spectral graph theory descends directly from spectral geometry, the study of differentiable manifolds through the spectra of associated differential operators. But the translation from spectral geometry to spectral graph theory has largely focused on results involving only a few extreme eigenvalues and their associated eigenvalues. Unlike in geometry, the study of graphs through the overall distribution of eigenvalues — the spectral density — is largely limited to simple random graph models. The interior of the spectrum of real-world graphs remains largely unexplored, difficult to compute and to interpret. In this paper, we delve into the heart of spectral densities of real-world graphs. We borrow tools developed in condensed matter physics, and add novel adaptations to handle the spectral signatures of common graph motifs. The resulting methods are highly efficient, as we illustrate by computing spectral densities for graphs with over a billion edges on a single compute node. Beyond providing visually compelling fingerprints of graphs, we show how the estimation of spectral densities facilitates the computation of many common centrality measures, and use spectral densities to estimate meaningful information about graph structure that cannot be inferred from the extremal eigenpairs alone.
Runner Up – Research track
Optimizing Impression Counts for Outdoor Advertising
RMIT University, Singapore Management University, Wuhan University, Huawei
Yipeng Zhang, Yuchen Li, Zhifeng Bao, Songsong Mo, Ping Zhang
Abstract: In this paper we propose and study the problem of optimizing the influence of outdoor advertising (ad) when impression counts are taken into consideration. Given a database U of billboards, each of which has a location and a non-uniform cost, a trajectory database T and a budget B, it aims to find a set of billboards that has the maximum influence under the budget. In line with the advertising consumer behavior studies, we adopt the logistic function to take into account the impression counts of an ad (placed at different billboards) to a user trajectory when defining the influence measurement. However, this poses two challenges: (1) our problem is NP-hard to approximate within a factor of O(|T |1−ε ) for any ε > 0 in polynomial time; (2) the influence measurement is nonsubmodular, which means a straightforward greedy approach is not applicable. Therefore, we propose a tangent line based algorithm to compute a submodular function to estimate the upper bound of influence. Henceforth, we introduce a branch-and-bound framework with a θ-termination condition, achieving θ 2 (1 − 1/e) approximation ratio. However, this framework is time-consuming when |U| is huge. Thus, we further optimize it with a progressive pruning upper bound estimation approach which achieves θ 2 (1 − 1/e − ϵ) approximation ratio and significantly decreases the running-time. We conduct the experiments on real-world billboard and trajectory datasets, and show that the proposed approaches outperform the baselines by 95% in effectiveness. Moreover, the optimized approach is around two orders of magnitude faster than the original framework.
Best Paper Award – ADS track
Actions Speak Louder than Goals: Valuing Player Actions in Soccer
KU Leuven, SciSports
Tom Decroos, Lotte Bransen, Jan Van Haaren, Jesse Davi
Abstract: Assessing the impact of the individual actions performed by soccer players during games is a crucial aspect of the player recruitment process. Unfortunately, most traditional metrics fall short in addressing this task as they either focus on rare actions like shots and goals alone or fail to account for the context in which the actions occurred. This paper introduces (1) a new language for describing individual player actions on the pitch and (2) a framework for valuing any type of player action based on its impact on the game outcome while accounting for the context in which the action happened. By aggregating soccer players’ action values, their total offensive and defensive contributions to their team can be quantified. We show how our approach considers relevant contextual information that traditional player evaluation metrics ignore and present a number of use cases related to scouting and playing style characterization in the 2016/2017 and 2017/2018 seasons in Europe’s top competitions
Runner Up – ADS Track
Developing Measures of Cognitive Impairment in the Real World from Consumer-Grade Multimodal Sensor Streams
Apple, Evidation Health, Eli Lilly and Company
Richard Chen, Filip Jankovic, Luca Foschini, Lampros Kourtis, Alessio Signorini, Nikki Marinsek, Melissa Pugh, Jie Shen, Roy Yaari, Vera Maljkovic, Marc Sunga, Han Hee Song, Hyun Joon Jung, Belle Tseng, Andrew Trister
Abstract: The ubiquity and remarkable technological progress of wearable consumer devices and mobile-computing platforms (smart phone, smart watch, tablet), along with the multitude of sensor modalities available, have enabled continuous monitoring of patients and their daily activities. Such rich, longitudinal information can be mined for physiological and behavioral signatures of cognitive impairment and provide new avenues for detecting MCI in a timely and cost-effective manner. In this work, we present a platform for remote and unobtrusive monitoring of symptoms related to cognitive impairment using several consumer-grade smart devices. We demonstrate how the platform has been used to collect a total of 16TB of data during the Lilly Exploratory Digital Assessment Study, a 12-week feasibility study which monitored 31 people with cognitive impairment and 82 without cognitive impairment in free living conditions. We describe how careful data unification, timealignment, and imputation techniques can handle missing data rates inherent in real-world settings and ultimately show utility of these disparate data in differentiating symptomatics from healthy controls based on features computed purely from device data
Test of Time Award
Cost-effective outbreak detection in networks
Carnegie Mellon University, Nielsen BuzzMetrics
Jure Leskovec, Andreas Krause, Carlos Guestrin,Christos Faloutsos, Jeanne VanBriesen, Natalie Glance
Abstract: Given a water distribution network, where should we place sensors toquickly detect contaminants? Or, which blogs should we read to avoid missing important stories?
These seemingly different problems share common structure: Outbreak detection can be modeled as selecting nodes (sensor locations, blogs) in a network, in order to detect the spreading of a virus or information asquickly as possible. We present a general methodology for near optimal sensor placement in these and related problems. We demonstrate that many realistic outbreak detection objectives (e.g., detection likelihood, population affected) exhibit the property of “submodularity”. We exploit submodularity to develop an efficient algorithm that scales to large problems, achieving near optimal placements, while being 700 times faster than a simple greedy algorithm. We also derive online bounds on the quality of the placements obtained by any algorithm. Our algorithms and bounds also handle cases where nodes (sensor locations, blogs) have different costs.
We evaluate our approach on several large real-world problems,including a model of a water distribution network from the EPA, andreal blog data. The obtained sensor placements are provably near optimal, providing a constant fraction of the optimal solution. We show that the approach scales, achieving speedups and savings in storage of several orders of magnitude. We also show how the approach leads to deeper insights in both applications, answering multicriteria trade-off, cost-sensitivity and generalization questions.
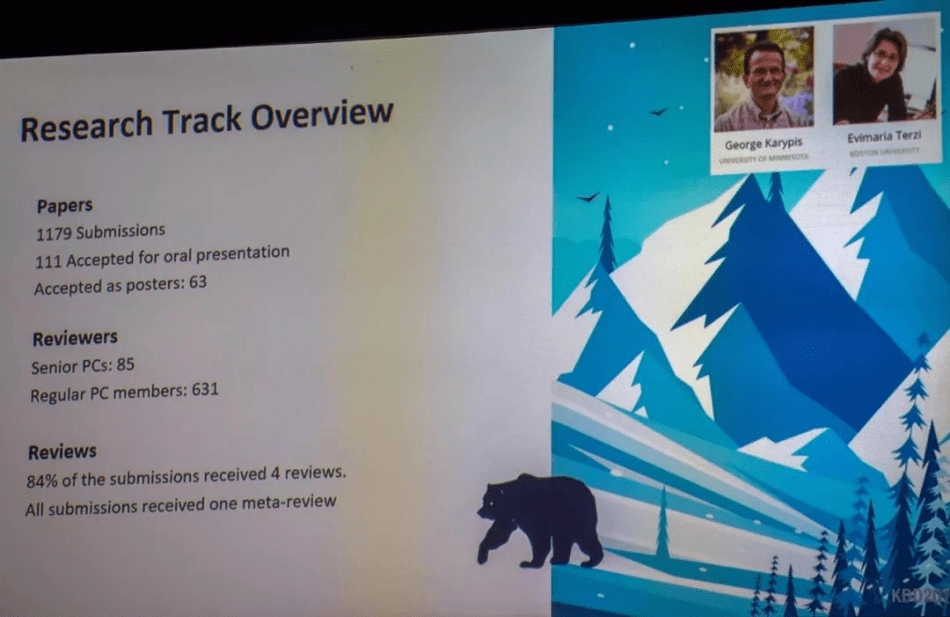
This year’s paper acceptance rate fell to 14 percent from last year’s 18 percent. KDD 2019 adopted a double-blind review system, with authors’ names and organizational information concealed from reviewers and vice versa. The conference also introduced an emphasis on reproducibility as “an important factor in the review process of the paper.” Only papers with a two-page appendix covering reproducibility would be considered for the KDD Best Paper Awards.
Journalist: Fangyu Cai | Editor: Michael Sarazen
Pingback: Data Science newsletter – August 8, 2019 | Sports.BradStenger.com