
Beijing-based computer vision unicorn Megvii Technology runs the world’s largest face-recognition technology platform, Face++. The company provides innovative solutions for object detection and image recognition using AI-powered techniques.
This week, Megvii (Face++) Chief Scientist Dr. Jian Sun and his research team will present multiple projects at the European Conference on Computer Vision (ECCV) 2018, one of the world’s top three international image processing and computer vision gatherings.
AI has done an impressive job solving visual recognition problems independently, but still lacks the human ability to visualize abundant information at a glance. For example, when a human looks at a living room they can easily parse concepts at multiple perceptual levels, e.g., scene, objects, parts, textures, materials, as well as the compositional structures linking detected concepts. Megvii defines this ability as Unified Perceptual Parsing (UPP). Accomplishing UPP with a learning framework called “UPerNet” is the subject of the recent paper Unified Perceptual Parsing for Scene Understanding by Dr. Sun et al., and one of the projects that will be presented at the ECCV.

The research team’s first challenge was creating a high-quality training dataset, which is the foundation of a learning network. No single existing image dataset could provide all the levels of visual information required for UPP, so the authors merged and standardized various labeled image datasets for specific tasks: ADE20K; Pascal-Context and Pascal-Part for scene, object and part parsing; OpenSurfaces for material and surface recognition; and the Describable Textures Dataset (DTD) for texture recognition. The result was the working dataset Broden+, with 57,095 images for model training.
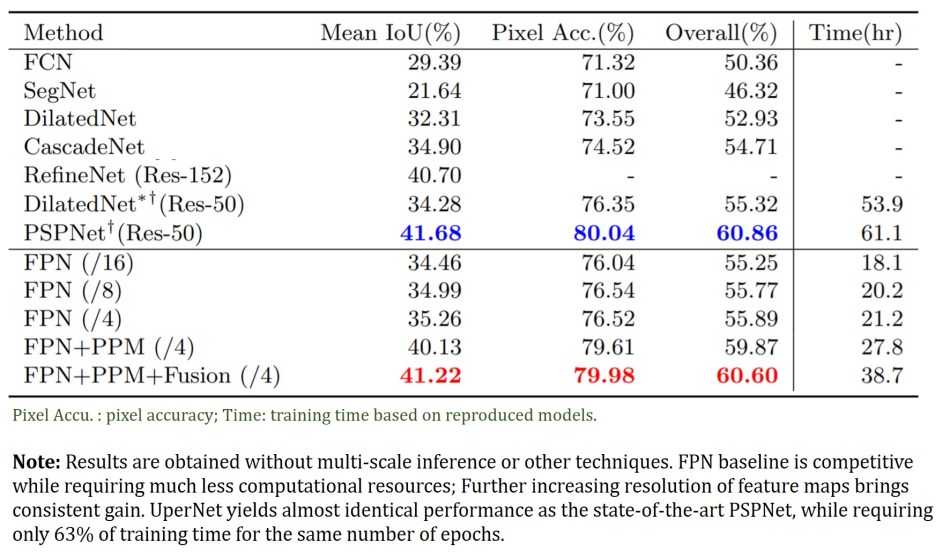
The authors overcame the annotation heterogeneity challenge (e.g., some annotations are image-level while some are pixel-level) by designing a multi-task framework to detect various visual concepts simultaneously. UPerNet was designed based on a Feature Pyramid Network (FPN), which exploits a top-down architecture to extract multi-level feature representations in an inherent and pyramidal hierarchy.
Because the FPN has an insufficient empirical receptive field, a Pyramid Pooling Module (PPM) is applied to the last layer of the backbone network before feeding it to the FPN top-down branch. In addition, a fusion of FPN feature maps is used in the object and part annotations for model performance enhancement.
A total of 36,500 images from 365 scenes in the Places-365 dataset were used for model validation. Both quantitative and qualitative results suggest UperNet is effective for unifying multi-level visual attributes simultaneously and has competitive model performance and training time requirement compared with current state-of-art methods.


UPerNet is also capable of exploring deeper understanding in a scene by identifying multi-compositional information such as scene-object, object/part-material, and material-texture relations from input images. Research results indicate the extracted information is reasonable and matches human understanding of compositional relations between these concepts.

The paper Unified Perceptual Parsing for Scene Understanding was published on arXiv in July. Related open source code is available at GitHub.
{kind=link}
Source: Synced China
Localization: Tingting Cao | Editor: Michael Sarazen
The UPerNet framework from Megvii really pushes the boundaries of unified perceptual parsing by tackling scene, object, part, and material understanding in one efficient architecture. If you are diving into multi-level visual scene interpretation, check it out for more resources.
I recently came across this article on UPerNet while exploring scene understanding research — fascinating how multi-level perceptual parsing is evolving. I’ve been experimenting with some of these concepts in this 3DTRELLIS app as well.
I also found Aiphototemplate really helpful.
The multi-level understanding in Megvii’s UPNet is impressive — the Seedance 2 tool takes a similar layered approach for video, parsing scenes at different temporal granularities. Great to see this paradigm spreading across modalities.
I also found the Hy 3D tool really helpful.
I really appreciate how this article highlights the practical ways technology can ease the mental load of parenting. Having a centralized space to organize family schedules, meal plans, and to-do lists makes such a difference in reducing that constant mental juggling. I also found printables.cloud really helpful for finding ready-made templates that streamline daily routines even further.
I also found kling-motion.com really helpful.
I also found this resource really helpful.
This is a very thorough overview of UPerNet’s multi-level approach to scene parsing. The way it integrates contextual cues across different scales reminds me of recent work over at crealitycloud.org. Looking forward to seeing these ideas evolve for real-time applications.
I also found perchance-ai-image.com really helpful.
I also found the Crayo AI tool really helpful.
I also found this tool really helpful.
This is a fascinating deep dive into UPerNet’s ability to parse visual scenes at multiple levels simultaneously — from pixels to objects to entire scenes. The unified approach really pushes the boundaries of what’s possible with semantic segmentation. I’ve been exploring similar scene understanding techniques at https://aiphoto-editor.com and this article provides excellent architectural insights that complement that work perfectly.
Interesting how UPerNet tackles scene understanding at multiple levels simultaneously — the pyramid pooling module approach feels very applicable for animation asset parsing where you need both broad layout context and fine detail recognition at once. The way it integrates PPM with feature pyramid networks seems like it could reduce the manual tagging burden for complex animation scenes considerably. I also found ai-for-animation.com really helpful.
I also found image-to-stl.org really helpful.
I also found check it out really helpful.
I also found this resource really helpful.
I also found this resource really helpful.
I also found Seedance 2 really helpful.
I also found an AI music generation tool really helpful.
This article on Megvii UPerNet’s multi-level visual scene interpretation is quite fascinating. It really delves into the complexities of how AI can process and understand visual information at different granularities, which is a significant leap forward. It reminds me of the advancements we’re seeing in multimodal AI, where combining different data types leads to richer understanding. For instance, creating cinematic AI videos from text, images, and audio references, like what Omni Flash does, requires a similar sophisticated interpretation of various inputs. I’m curious to see how these multi-level interpretation techniques will evolve further in video generation and other visual AI applications.
This is a fascinating deep dive into the UPerNet framework for multi-level scene interpretation. I have been reading more about how backbone architectures influence segmentation quality, and I came across this Samaudiolab AI tool that applies similar hierarchical reasoning to audio processing tasks. It’s impressive to see cross-domain parallels in how multi-scale feature fusion can generalise beyond vision.
Great breakdown of the multi-level parsing approach! The ability to interpret scenes at different granularities simultaneously is really what separates modern deep learning pipelines from earlier single-scale methods. I’ve found that applying similar hierarchical techniques to face segmentation and reconstruction yields surprisingly robust results too. I also found Deepfacelab really helpful.
Fascinating breakdown of UPerNet — merging ADE20K, Pascal-Context, OpenSurfaces and DTD into Broden+ was such a pragmatic answer to the annotation heterogeneity problem. It’s wild how this scene-parsing lineage eventually shows up in consumer generative tools; I play around with renderflowai.com for image generation and you can really feel the scene coherence improving year over year. Thanks for covering the ECCV presentation.
I also found aiphotoassistant.com really helpful.