

Introduction
In recent years, neural machine translation (NMT) is becoming more and more popular, due to its more fluent translation results. However, statistical machine translation (SMT) is better in translation adequacy. To combine the advantages of these two methods, the authors of this paper first adapts the multi-source NMT model, by employing different encoders to capture the semantics of the source language, then the decoder is used to generate the final output by the multiple context vector representations coming from the encoder. Additionally, the author further designs a smart strategy to simulate the real training data for neural system combination.
The Architecture of Neural Combination System
The author uses a two-step solution towards neural system combination:
- For a source sentence, generate translations with phrase-based SMT (PBMT), hierarchical based SMT (HPMT) and NMT.
- Design a multi-source sequence-to-sequence model that takes as input the three translation results of PBMT, HPMT and NMT, and produces the final target language translation.
The following figure shows their proposed model for neural system combination, where the input can be regarded as the source sentence and the results of MT systems.

To make it easier for understanding, we discuss the paper in a reverse order. We discuss from the final word classification layer to the combined encoder at the beginning.
As the figure shown above, the combination model proposed in this paper is an adaptation from multi-source NMT model, where different encoders are based on the best translation by different NMT and SMT systems. The combination of SMT and NMT can provide both the fluency and the adequacy in translation as described in the paper.

here alpha_{ji}^k means the weight of i-th encoder node of the k-th system in the j-th decoder step, where:

e_{ji} describes how well s ̃_{j-1} and h_i match.
h_i is the concatenation of [h_i_forward, h_i_backward] from a bi-directional GRU, and s ̃_{j-1} = GRU (s_{j-1}, y_{j-1}) is an intermediate state calculated by a GRU function, given previous hidden state s_{j-1} and previous output y_{j-1}.
After knowing the h_i, the k-th system context vector c_{jk} at decoder step j can be calculated by:
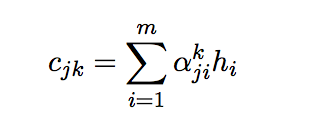
which is a weighted sum of the source encoder state h_i, given the weighting factor alpha_{ji}^{k}.
After knowing the system context vector context vector c_{jk}, it is easy to calculate the normalized item beta_{jk} for each of them in order to combine different system context vector:

where s ̃_{j-1} = GRU (s_{j-1}, y_{j-1}) is an intermediate state calculated by a GRU function and c_{jk} is the k-th system context vector.
After knowing the normalized vector beta_{jk} for k-th system context vector, the final system combination vector can be calculated by:

where c_j is the weighted sum of context vectors of k systems, as illustrated in the above figure.
After knowing the context vector, the probability of the next word y_j, given previously generated target sequences Y_{<j} and the results sequence Z = (Z^n, z^p, Z^h, … Z^k) of K systems for the same source sentence can be calculated as:

the c_j is known by previous derivation, y_{j-1} is the previous output embedding feature, and the state of j-th decoder step s_j is calculated by:

which is a GRU function given an immediate state s ̃_{j-1} = GRU (s_{j-1}, y_{j-1}) and system combined context vector c_j.
The author in this paper designed a smart way for training data simulation: they randomly divided the training bilingual corpara into two parts, they trained three different MT systems of half of them, and the source sentences of the other half into target translations. This way, the pre-translated sentences can have a better quality for later combination usecase.
Experiments and Results
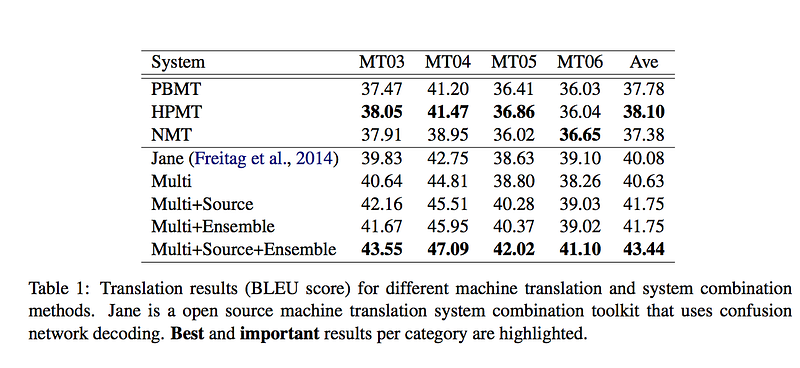
As shown in the above figure, the results on NIST 03–06 is quite good. The multi-combination system itself already got an average BELU of 40.63, better than the best one (HPMT (38.10)) of the individual MT system. When adding the source sentence for training (multi-source combination), the result further improves to 41.75 BELU score. Finally, when they ensemble different decoding models, the results sees another improvement to 43.44 BELU score.

As shown in the above figure, the NMT model itself cannot translate the OOV word zuzhiwang into a correct word, but the PMBT and HPMT can (kongbu zuzhiwang → terrorist group). After the neural system combination training, the multi-combination system can translate the OOV word into a correct word with proper grammar.
Reviewer’s Thoughts
This paper took me quite a while to read, since it’s not a general translation pipeline. Instead, the central idea is to take advantage of NMT and SMT by adapting the multi-source NMT model. They use NMT and PBMT systems to pre-translate the inputs into target translations, and then generate the final target hypothesis using these pre-translations. They show that the results can be further improved by jointly training with source language input sentences, so the model then become a multi-source language models. Although they designed a good way to simulate the training data for system combination and got a very good results, I still think it really takes too much pre-processing and hand-crafted designs before the final output. The decoding speed in practical scenarios is also still unknown. Compared to this pre-translated technique, I think it would be a better way to directly use some PBMT features, like language model and phrase tables during decoding beam searching, to help finding a better n-best hypothesis, which would be a smarter way to combine the advantages of different MT systems.
Technical Analyst: Shawn Yan | Reviewer: Hao Wang | Source: https://arxiv.org/pdf/1704.06393.pdf
0 comments on “Neural System Combination for Machine Translation”