
The study of unmanned vehicles is no longer a simple process of identifying traffic lights or road signs, it has been extended to several scenes in life. One crucial standard in measuring autonomous vehicles is whether the autonomous vehicles can go through intersections with no signals. In this paper, the authors provide us with a new strategy of using Deep Reinforcement Learning. Compared with the current rule-based methods, which means to store and manipulate the knowledge and interpret the information in a useful way, the authors show us that using Deep Reinforcement Learning can achieve better performance in task completion time and goal success rate etc. The average success rate can reach up to 99.64%, and the time it takes to take a trail successfully is shortened to 5.5 second on average. However, they point out that there’s more efforts required to increase its robustness.
1. INTRODUCTION:
Even for human drivers, 20% of all accidents occur at intersections [1]. One can only imagine how difficult it is for autonomous vehicles to learn this well. To successfully go through a intersection, three things should be done:
- Understand vehicle dynamics
- Interpret the intents of other drivers
- Behave predictably so other drives have time to take appropriate responses
This should balance numerous conflicting objectives like safety, efficiency, and minimizing the disruption of traffic.
There are mainly two groups of rule-based methods which have been applied to intersection handling: cooperative methods [2] and heuristic methods [3]. Cooperative methods are not scalable to general intersection handling, due to the requirement of vehicle-to-vehicle communication. The state-of-the-art is a rule-based method based on time-to-collision (TTC) [4]. TTC has a lot of benefits, such as reliability, but it still has limitations. First, TTC models ignores almost all information about driver intent, due to the assumption of constant velocity. Secondly, human drivers’ unpredictable behavior complicates the use of rule-based algorithms. Finally, there are many cases indicate that using TCC may be overly cautious, which will create unnecessary delays.
As the authors mentioned, there are mainly three machine learning based methods that have been used for intersection handling. They are imitation learning, online planning, and offline learning. The authors chose the offline learning method, and provided an explanation on why imitation learning and online planning are not appropriate. For imitation learning, it cannot offer a solution if the agent finds itself in a state that hasn’t been taught. Online planners rely on the existence of an accurate generative model. Figure 1 shows the process of crossing the busy intersections.

2. APPROACH
In this section, the authors regard intersection handling as a reinforcement learning problem. They use a Deep Q Network(DQN) to learn the state action value Q-function. The approach is divided into five parts:
- Reinforcement Learning (RL).
This part is to introduce Reinforcement Learning, and I’ll use the simplest way to describe the process of Reinforcement Learning. In the RL model, an agent in state st takes an action at according to the policy p at time t. The agent transitions to the state st +1, and receives a reward rt. This is formulated as a Markov Decision Process (MDP), and Q-learning is used to perform the optimization.
- Q-learning.
This part introduces Q-learning, and I recommend the readers to learn Q-learning first, which will make it easier to read the paper. The essence of Q-learning is using average value of the action value function Qp(s,a) to estimate the actual value. It will be updated when the data is added.
- Dynamic Frame Skipping.
Dynamic Frame Skipping is a simplified version of options [5], it allows an agent to select actions over extended time, which will improve the learning time of the agent.
- Prioritized Experience Replay.
The authors use experience replay to break the correlations between sequential steps of the agent. Previous trajectories are stored by an experience replay buffer, and this means important sequences that happen less frequently can be sampled. This will avoid the computation of a rank list, and the samples to balancing reward across trajectories will replace the computation.
- State-Action Representations.
Because the use of sensors in autonomous vehicles, a lot of state and action representations are allowed. In this paper, the authors present two representations. The first is sequential actions, where the desired path is provided to the agent and the agent determines to accelerate, decelerate, or maintain velocity. The second is Time-to-Go, where the agent determines the time to wait or go. The former can make us be able to observe whether allowing more complex behaviors can bring benefits, the latter focuses on departure time and allow us to probe how departure time changes can affect performance.
3. EXPERIMENTS
In this part, the authors train two DQNs (Sequential Actions and Time-to-Go) based on a variety of intersection scenarios. They compare the performance against the heuristic Time-to-Collision (TTC) algorithm. The TTC policy uses a single threshold to decide when to cross, and serves as a baseline in the authors’ analysis. The authors use the Sumo simulator [6] to run the experiments. This simulation package help users simulate a variety of traffic conditions in different scenarios. It helps model road networks, road signs, traffic lights, a lot of vehicles, and it can facilitate online interaction and vehicle control. There are five different intersection scenarios, as shown in Figure 2. The authors give a series of parameters to set the scenarios, and four metrics to evaluate the method: percentage of successes, percentage of collisions, average time and average braking time. For TTC and Time-to-Go DQN, all state representations ignore occlusion and assume that all cars are always visible.
The sequential action network is a fully connected networks with leaky ReLU activation functions. And there are 3 hidden layers of 100 nodes each, and a final linear layer with 12 outputs, which correspond to three actions (accelerate, decelerate, maintain velocity) at four time scales (1, 2, 4 and 8 time steps). For the Time-to-Go DQN network, it uses a convolutional neural network with two convolutional layers and one fully-connected layer. The first convolutional layer has 32 6 × 6 filters with stride two, the second convolution layer has 64 3 × 3 filters with stride 2. The fully connected layer has 100 nodes. All layers use leaky ReLU activation functions. The final linear output layer has five outputs: a single go action, and a wait action at four time scales (1, 2, 4, and 8 time steps). In this experiment, the experience replay buffers store 100,000 time steps, and there are two buffers for collisions and for both successes and timeouts. For the reward, the authors used +1 for success, -10 or a collision and -0.01 for step cost.

4. RESULT
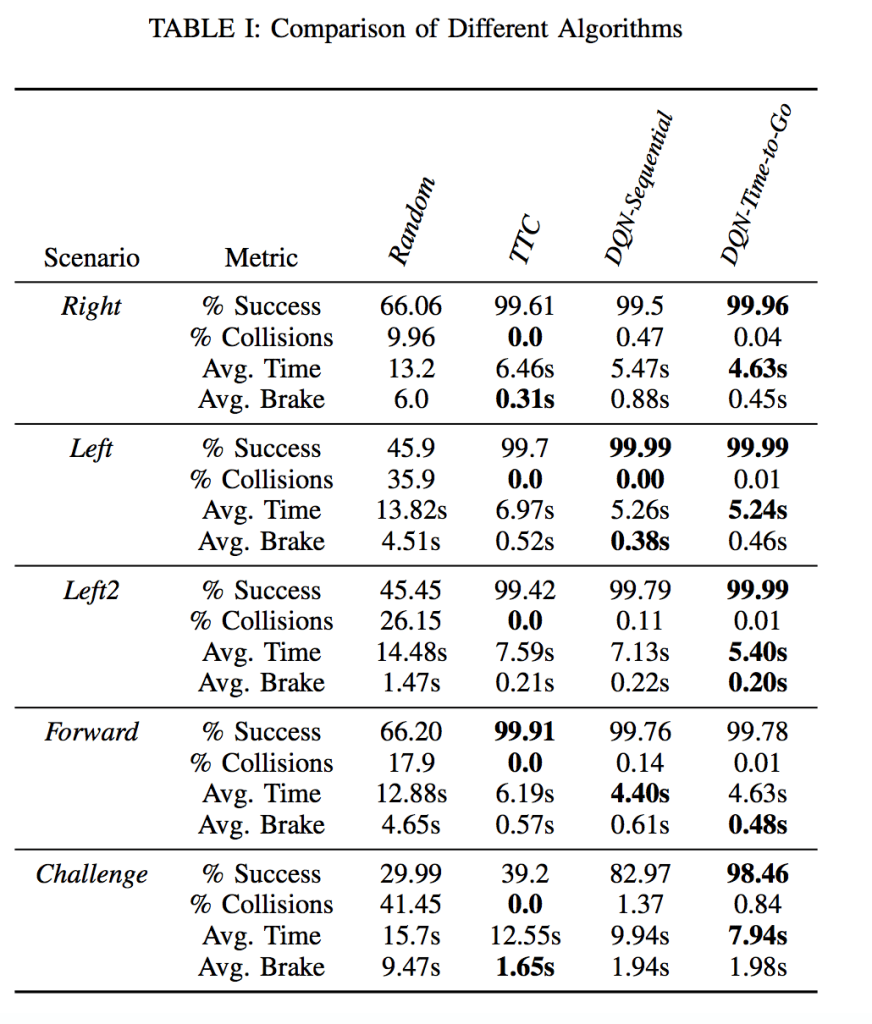
The results can be seen in Table 1, Figure 3, Figure 4. And we can see the features:
- TTC method didn’t have collisions in any of the scenarios. Among DQN method, DQN Time-to-Go had substantially lower collision rate than DQN-sequential.
- DQN methods are substantially more efficient in reaching the goal than TTC. On average, DQN Time-to-Go was 28% faster in reaching to goal than TTC, and DQN Sequential was 19% faster than TTC. This means the DQN methods have potential to reduce traffic jams.
- Except in one case, DQN Time-to-Go has the best results with the highest success rates, as shown in Figure 3.

- While DQNs are substantially more efficient, they are not good at minimizing the number of collisions as TTC.
- In Figure 4, we can see that the DQN’s performance dominates the performance of TTC as the authors trade off speed vs. safety. This suggests that designing an algorithm that has zero collision rate is possible.

Due to the fact that DQN doesn’t achieve a zero percent collision rate, the authors try to find a way to solve this problem, because a zero percent collision rate is very important. The authors suspect that training on multiple scenarios will improve the performance according to the core principles of multi-task learning [7]. Figure 5 shows the transfer performance and the specific data can be seen in Table II and Table III, which will help the authors get an understanding of how well a deep net system can generalize. We can see that the more challenging scenarios transfer well to easier domains, but changing the number of lanes creates interference.


The authors then give a qualitative analysis. In the analysis, the authors point out that the DQNs can accurately predict that traffic in distant lanes will have passed by the time the ego car arrives at the lane. Also, the DQN driver is able to anticipate whether oncoming traffic will have sufficient time to brake or not. The authors also give the explanation of why there are some collisions. The collisions are due to discretization effects where the car nearly misses the oncoming traffic. The authors also point that TTC often waits until the road is completely clear, as shown in Figure 6, and it’s not good enough for practical conditions.

5. CONCLUSION
For this paper, there are three contributions as the authors mentioned. The first contribution is the novel idea of combining several recent deep learning techniques to improve performance. The second contribution is the analysis of how well the DQN performs compared with TTC in five different intersection simulation scenarios. The third contribution is the analysis of how well the trained DQN policies transfer to different scenarios.
In my opinion, there are still two things to improve in the future. First is the architecture of the convolutional neural networks. With more complex scenarios, deeper neural networks can be much better. We can find the same conclusion in reference [8], where a self-driving company regards the deep learning as the only viable way to make a trustworthy unmanned car, because there are a lot of conditions and many things that are difficult and nuanced. The other is about the collision rate. I think there should be another way to reduce the collision rate to zero, because safety is the most important aspect for unmanned cars. We cannot achieve this goal only by the model or the algorithm, and there are other ways to solve this. At Audi, the engineers applied millimeter-wave radar, laser radar, camera, ultrasonic probe and so on to make the mutual compensation and verification, which can also help the car to make the correct decision.
6. REFERENCE
[1] National Highway Traffic Safety Administration, “Traffic Safety Facts, Tech. Rep. DOT HS 812 261, 2014. [Online]. Available: https://crashstats.nhtsa.dot.gov/Api/Public/Publication/812261
[2] Hafner, Michael R., et al. “Cooperative collision avoidance at intersections: Algorithms and experiments.” IEEE Transactions on Intelligent Transportation Systems 14.3 (2013): 1162-1175.
[3] Alonso, Javier, et al. “Autonomous vehicle control systems for safe crossroads.” Transportation research part C: emerging technologies 19.6 (2011): 1095-1110.
[4] Minderhoud, Michiel M., and Piet HL Bovy. “Extended time-to-collision measures for road traffic safety assessment.” Accident Analysis & Prevention 33.1 (2001): 89-97.
[5] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. Vol. 1. No. 1. Cambridge: MIT press, 1998.
[6] Krajzewicz, Daniel, et al. “Recent development and applications of SUMO-Simulation of Urban MObility.” International Journal On Advances in Systems and Measurements 5.3&4 (2012).
[7] Caruana, Rich. “Multitask learning.” Learning to learn. Springer US, 1998. 95-133.
Source: https://arxiv.org/abs/1705.01196
Author: Shixin Gu | Reviewer: Hao Wang
0 comments on “Navigating Intersections with Autonomous Vehicles using Deep Reinforcement Learning”