

Introduction
This paper introduces an interesting application of conditional generative adversarial network (cGAN) for face aging. That is, you can use this cGAN to synthesize the face images of one person at different ages. For research area, this method can be used to improve the performance of “cross-age facial recognition”. For daily application, except for entertainment, it can also be used for finding missing children.
This paper mainly has two contributions:
- They design Age Conditional Generative Adversarial Network (acGAN) to generate face images within required age categories.
- They propose a latent vector optimization approach allowing acGAN to reconstruct input face image preserving the original person’s identity.
2. Methods and Experiments
How does this acGAN work?
As shown in the following figure, after the acGAN is trained, we first use Identity Preserving Optimization to find an optimal latent vector z_star that allows us to generate a reconstructed face image x_bar as close as possible to the original image x with age label y_0. We then let the acGAN use this latent vector z_star with a target age label y_target to generate the final face image with target age.
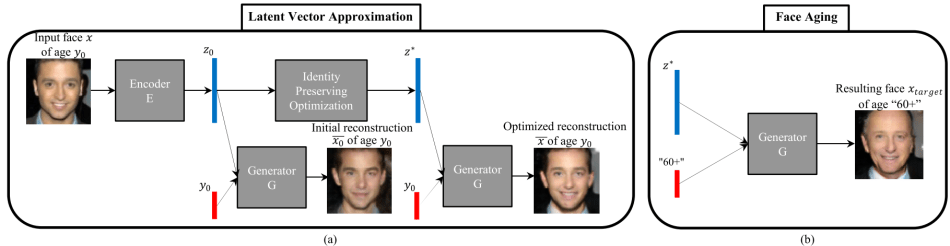
2.1 Training acGAN
Similar to traditional cGAN, the training process of this acGAN can be expressed as an optimization of the following function (1):

where theta_G and theta_D are parameters of G and D respectively, y is the additional label for training set x (condition for x). In this project, y is a six-dimensional one-hot vectors for six different age categories.
2.2 Approximative Face Reconstruction
In order to generate face image using a given initial face image with a target age label, a map of an input image x with label y to a latent vector z should be constructed, because cGAN does not have an explicit mechanism for this kind of inverse mapping. Therefore, the authors used synthetic dataset of 100K pairs to train an encoder, which is a neural network to approximate the inverse mapping. This encoder is trained to minimize the Euclidean distances between estimated latent vector z_0 and the ground truth latent vector.
But the authors found that although the approximation z_0 result in visually good face reconstructions, the identity of the original image is lost in about 50% of cases. Thus, they proposed a novel “Identity-Preseving” approach to improve this z_0.
The key trick is using a given face recognition neural network FR, to embed the input face image x as FR(x) and to embed the reconstructed one x_bar as FR(x_bar). Minimizing the Euclidean distance between these embeddings rather than that between x and x_bar (also: pixel-wise optimization) make it possible to maintain the identities of original face images.
Concretely, the following figure illustrates the difference between “Pixel-Wise” method and “Identity Preseving (IP)” method. Part (c) shows that the facial expression or hair-style can be better maintained using IP method. Part (d) shows the generated images using IP latent vector with age label as input of this acGAN.

The following figure shows the performance of this acGAN using a random latent vector with age labels:

In oder to quantify the difference between the IP-method and Pixelwise-method, the authors used “OpenFace” to recognize the generated face images as the metric. From this table, it is obvious that the IP-method can maintain more face-features (face identities) through this generation process, because the FR score is much higher than that of Pixel-Wise or initial ones.

3. Conclusion
The main advantage of this acGAN is that they use “Identity-Preserving” latent vector optimization approach to maintain the original person’s identity in reconstruction.
This method can also be used for synthetic augmentation of face datasets and for improving the robustness of face recognition solutions in cross-age scenarios.
4. Thoughts from the Reviewer
General Comments:
This paper proposed a method to synthesize face images at a given age using acGAN. From the results above, this method has achieved its goal at a high level. The new idea from this paper is that they use a state-of-art face recognition network to embed input face images to gain the high-level feature expression of this face, such that the person’s identity can be maintained through the reconstruction. Besides, the author uses the “OpenFace” to recognize the generated faces to evaluate the performance of face reconstruction and generation of this acGAN, which is very convincing.
This paper extensively lacks citation to the broader work of content-style disentanglement and style transfer lines of work. The proposed idea of using GAN solving this problem, combined with optimization techniques can be seen as a combination of both. Yet the comparison could be made better, to the related papers.
Possible Problems:
- From the figures above, we can tell that the generated faces in age-group of “0-18” and “60+” have clear differences, but there is little differences between the other 4 groups, especially for female faces. One possible reason could be the authors not taking “making up” into consideration when pre-processing the training data. Application of make up can often confuse age prediction in daily life. In other words, other than training using “IP” being very important for this project, the selection and pre-processing of training data also plays a key role.
- There are only 6 age groups in this project, each separated by a range of ten years. This setting is appropriate for the people at the age ranging from 30 to 60 years old. But for children and teens, their faces change much more quickly as they age. So the result from the “0-18” age group is not as convincing as other groups.
Possible Improvements:
- Divide the first age group into several sub-groups such that the generated results would be more convincing.
- Only use face images without making up to train the encoder part, so key feature in terms of age can be extracted and maintained.
Comparison with Prior Works:
First, I use https://how-old.net/ from Microsoft to predict the ages of generated faces. The result is as follows:

For male faces, this acGAN works relatively well, except for the age group of “40-49” and “50-59”. For female faces, as mentioned before, the differences between the first several groups are too small such that they are classified into the same age group.
On the other hand, the age-prediction web-app can detect the 12 generated faces correctly, which means the acGAN can surely generate face images for synthetic augmentation of face datasets.
Second, I use APP “FaceApp” and “Oldify” to age faces. The result is as follows:

The first two images are obtained using FaceApp (based on neural network), the last one is obtained using Oldify. Obviously, the method proposed in this paper has much better results than these popular smart phone applications. This method can generate faces at different ages, which is also unique compared to these two applications.
Author: Yiwen Liao | Technical Review: Hao Wang, Jake Zhao| Localized by Synced Global Team: Xiang Chen
Thank you for your blog about age-cgan.I read this paper and I have a question that there is not a description about the structure of D,G and E in this paper.Could you have an idea about the architecture of the D,G and E in Age-cGAN.Thx a lot!
Thank you for your blog about age-cgan.I read this paper and I have a question that there is not a description about the structure of D,G and E in this paper.Could you have an idea about the architecture of the D,G and E in Age-cGAN.Thx a lot!