
After Go and Texas Hold’em, RTS game “StarCraft” is becoming the next research target for artificial intelligence researchers. Researchers from Alibaba and University of London (UCL) have recently published a new study, claiming that multiple game units controlled by artificial intelligence are now able to develop tactics similar to human players using unsupervised learning. This new approach, which collaborates multiple artificial intelligence networks, may become a new research focus.
Over the past decade, AI technology made huge leaps. In the case of supervised learning, machines have shown capabilities beyond human cognizance for image and speech recognition. For games with designated targets, monomer artificial intelligence (single agent) had already beaten the strongest human players in Atari, Go, and Texas Hold’em.
However, a large part of human wisdom lies in social and collective interactions, which is the basis for the realization of general artificial intelligence.
The next big challenge for artificial intelligence is to enable different agents to cooperate and compete. For researchers, classic real-time strategy game (RTS) like “StarCraft” is an excellent environment for experiments. Each player controls different arms and is required to start fighting under different terrain conditions.
Due to its variations, the “StarCraft” series are more difficult to AI than Go, and provoked the profound interest of research companies like DeepMind.
At the same time, collaborative learning of such a large multi-agent system is confronted with the limitations of computer performance: parameter space will increases exponentially as the number of involved agents increase, which means that any joint learning approach will be ineffective.
For the purpose of their study, researchers from Alibaba and UCL set the multi-agent StarCraft combat mission to zero and random. Different agents communicate with each other through a new bi-directional coordination network (BiCNet), and learning is done through an evaluation-decision-making process. In addition, researchers also proposed the idea of sharing parameters and dynamic grouping to solve the problem of scalability.
Paper Source:https://arxiv.org/abs/1703.10069
Paper Excerpt: Multiagent Bidirectionally-Coordinated Nets for Learning to Play StarCraft Combat Games
Real-world artificial intelligence (AI) applications often require multiple agents to work in a collaborative effort. Efficient learning for intra-agent communication and coordination is an indispensable step towards general AI. In this paper, we take StarCraft combat game as the test scenario, where the task is to coordinate multiple agents as a team to defeat their enemies. To maintain a scalable yet effective communication protocol, we introduce a multiagent bidirectionally-coordinated network (BiCNet [‘bIknet]) with a vectorised extension of actor-critic formulation. We show that BiCNet can handle different types of combats under diverse terrains with arbitrary numbers of AI agents for both sides. Our analysis demonstrates that without any supervisions such as human demonstrations or labelled data, BiCNet could learn various types of coordination strategies that is similar to these of experienced game players. Moreover, BiCNet is easily adaptable to the tasks with heterogeneous agents. In our experiments, we evaluate our approach against multiple baselines under different scenarios; it shows state-of-the-art performance, and possesses potential values for large-scale real-world applications.
 Figure 1: Bidirectionally-Coordinated Net (BiCNet)
Figure 1: Bidirectionally-Coordinated Net (BiCNet)
 Figure 2: Coordinated move without collision in combat 3 Mariners (ours) vs. 1 Super Zergling (enemy). The first two (a) and (b) illustrate that the collision happens when the agents are close by during the early stage of training; and the last two (c) and (d) illustrate coordinated moves over the well-trained agents.
Figure 2: Coordinated move without collision in combat 3 Mariners (ours) vs. 1 Super Zergling (enemy). The first two (a) and (b) illustrate that the collision happens when the agents are close by during the early stage of training; and the last two (c) and (d) illustrate coordinated moves over the well-trained agents.
 Figure 3: Hit and Run tactics in Combat 3 Marines (ours) vs. 1 Zealot (enemy).
Figure 3: Hit and Run tactics in Combat 3 Marines (ours) vs. 1 Zealot (enemy).
 Figure 4: Coordinated over attack in combat 4 Dragoons (ours) vs. 2 Ultralisks (enemy).
Figure 4: Coordinated over attack in combat 4 Dragoons (ours) vs. 2 Ultralisks (enemy).
 Figure 5: Coordinated cover attack in combat 3 Marines (ours) vs. 1 Zergling (enemy).
Figure 5: Coordinated cover attack in combat 3 Marines (ours) vs. 1 Zergling (enemy).
In the above three Marines against the enemy task (Figure 5), researchers adjusted the number of enemies and the Zergling’s blood and attack power several times. The experiment found that BiCNet in the enemy’s blood volume to be higher than 210, the attack power of 4 using the trap strategy, and the Zergling‘s default blood volume is 35, hit points is 5.
 Table 1: Winning rate against difficulty settings by hit points (HP) and damage. Training steps: 100k/200k/300k.
Table 1: Winning rate against difficulty settings by hit points (HP) and damage. Training steps: 100k/200k/300k.
 Figure 6: AI learns “focus fire” in combat 15 Marines (ours) vs. 16 Marines (enemy).
Figure 6: AI learns “focus fire” in combat 15 Marines (ours) vs. 16 Marines (enemy).
 Figure 7: Coordinated heterogeneous agents in combat 2 Dropships and 2 Tanks vs. 1 Ultralisk.
Figure 7: Coordinated heterogeneous agents in combat 2 Dropships and 2 Tanks vs. 1 Ultralisk.
 Figure 8: “batch_size” and “skip_frame” effects towards the method based on “2 Marines vs. 1 Super Zergling” scenario.
Figure 8: “batch_size” and “skip_frame” effects towards the method based on “2 Marines vs. 1 Super Zergling” scenario.
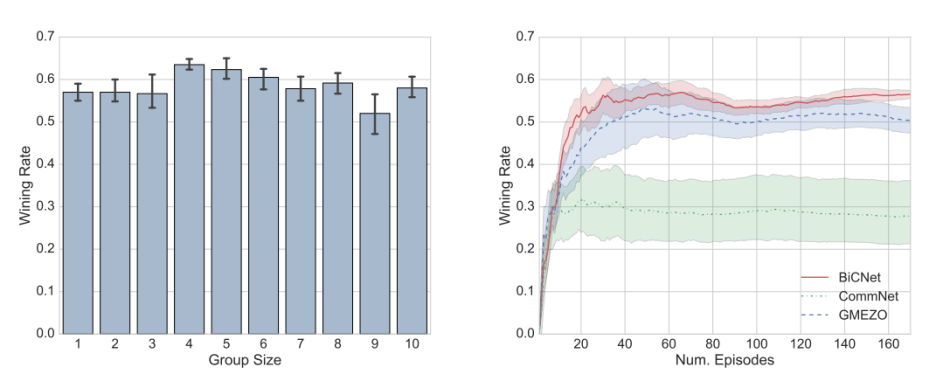 Figure 9: (left) Wining rate vs. group size in combat 10 Marines vs. 13 Zerglings”
Figure 9: (left) Wining rate vs. group size in combat 10 Marines vs. 13 Zerglings”
Figure 9: (right) Learning Curves in Combat “10 Marines vs. 13 Zerglings”, BiCNet outperformed all.

BiCNet is a multi-agent enhanced learning framework that utilizes bidirectional neural networks. It constructs a vectorized assessment-decision approach, where each dimension corresponds to an agent. The coordination between agents is done through a two-way internal communication. Through end-to-end learning, BiCNet can successfully learn a variety of effective collaborative strategy. This study proves that the system can coordinate various arms in the real-time strategy game “StarCraft”, resulting in a variety of effective tactics. In the experiment, the researchers found that there was a strong correlation between the specified incentive and the learning strategy. They plan to further study the relationship, explore how agents communicate in the network, and whether they will generate a specific language. In addition, when both sides use a deep multi-agent model for the game, the study of the Nash equilibrium will also be a very interesting research topic.
Original Article from Synced China http://www.jiqizhixin.com/article/2586 | Author: Peng Peng, Zenan Li| Localized by Synced Global Team: Meghan Han
Pingback: Alibaba’s New Study on Artificial Intelligence: Achieving Multi-arms Cooperative Gaming in “StarCraft” – AI Update
Pingback: Synced | Unveiling China’s Mysterious AI Lead: Synced Machine Intelligence Awards 2017
Hey guys, after a crazy long day at work, I needed some kind of outlet, so I decided to try my luck online. The first few minutes were pretty depressing, nothing was working out for me, and I was starting to think I was just having a bad day with everything I touched. But then I changed my approach, took a bigger risk, and suddenly luck smiled on me in a way I couldn’t believe. On my cousin’s direct recommendation, I tried the spingranny casino and was very interested to find that they offer local promotions for users from the Czech Republic that you won’t find anywhere else. The feeling of victory was absolutely fantastic, and it still puts a smile on my face. If you’re looking for honest entertainment with a real chance of winning, definitely give it a try.